 Marina Lyubimova
Marina Lyubimova

The SII-GAIR team has introduced daVinci-LLM-3B, a compact large language model released via Hugging Face that punches well above its weight class. As Adina Yakup reported, the model is trained on 8 trillion tokens with a fully transparent pipeline and backed by over 200 ablation studies. The release also introduces a "Data Darwinism" framework spanning levels L0 through L9, designed to refine training efficiency and improve output quality.
Benchmark Results Show daVinci-LLM 3B Matching Larger AI Models
Benchmark results confirm that daVinci-LLM-3B performs in line with both 3B and 7B-class models across multiple domains. In general benchmarks, the model scores 52.96, closely matching Qwen2.5-3B at 55.16 and OLMO-3-7B at 55.13.
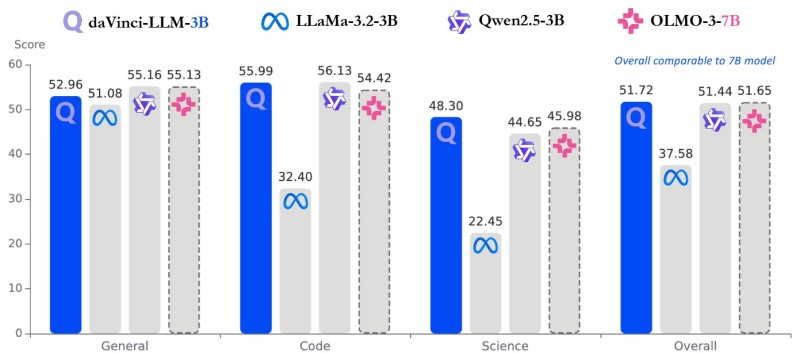
The coding results are where daVinci-LLM stands out most clearly:
- Coding tasks: 55.99, significantly ahead of LLaMa-3.2-3B at 32.40
- Science benchmarks: 48.30, compared to 44.65 for Qwen2.5-3B and 45.98 for OLMO-3-7B
- Overall score: 51.72, placing it on par with 7B-class systems
daVinci-LLM-3B achieves overall parity with 7B-class models, which cluster around similar performance levels despite having more than twice the parameters.
This is covered in broader context in AI Industry Update: LLM Agent Consensus Still Fails at Scale, which tracks how efficiency gaps between model sizes are increasingly becoming a central theme across the industry.
Data Darwinism: How Training Strategy Is Replacing Parameter Scale
The results highlight a key trend taking shape across the AI sector: efficiency gains are narrowing the gap between smaller and larger models. Rather than relying on parameter scaling alone, daVinci-LLM-3B demonstrates how large-scale token exposure and structured optimization can deliver competitive outcomes without ballooning model size.
Innovation increasingly focuses on data quality, training pipelines, and optimization techniques rather than sheer model size.
This aligns with the direction the broader industry is heading, where data quality and pipeline design are becoming the primary levers for performance improvement. LLM Alignment Reduces Real-World Human Behavior Accuracy by Nearly 10% adds another dimension to this picture, showing how training decisions at the methodology level carry real consequences for model behavior in practice.
Smaller AI Models Reshaping Deployment and Infrastructure Expectations
This development signals intensifying competition in the AI landscape, particularly as firms race to deliver cost-efficient, high-performance models. As smaller models approach the capabilities of larger systems, the implications extend well beyond benchmarks - deployment flexibility and infrastructure costs become direct beneficiaries.
The emergence of daVinci-LLM-3B suggests that the next wave of AI progress may be defined less by who can build the biggest model and more by who can extract the most from a leaner one.
 Marina Lyubimova
Marina Lyubimova


