 Saad Ullah
Saad Ullah

Efficient real-time decision-making is one of the hardest challenges in AI robotics. A new development called CompACT aims to solve that by drastically reducing the visual data an AI needs to plan its next move - without sacrificing accuracy.
CompACT is a compact discrete tokenizer that compresses visual observations into just eight tokens. Designed for use in latent world models, it lets AI systems represent entire visual scenes in a minimal form - a critical step forward for robotics deployments already hitting 90% task accuracy in real production environments.
How the 8-Token Architecture Works
The system works in two stages. First, an encoder converts input images into a small set of discrete tokens. Then a decoder reconstructs the visual scene to verify key information is preserved.
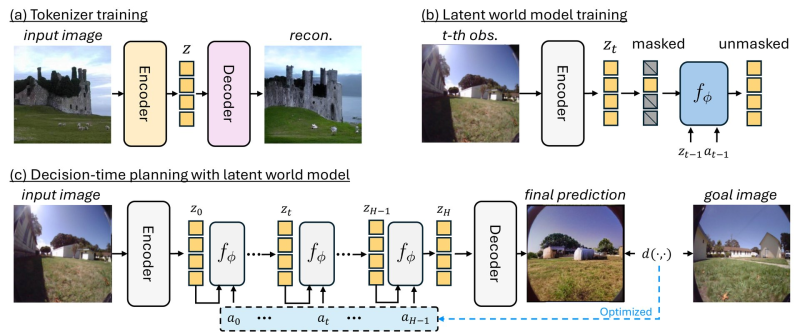
These eight tokens feed directly into a latent world model, which predicts future states based on past observations and actions. Running on eight tokens instead of large visual feature maps cuts the computational load dramatically - part of a wider industry shift where AI memory systems are achieving 10x efficiency gains as RAG becomes obsolete.
40x Speed Gains and Real-World Deployment
That speed advantage matters in production environments. The model pre-evaluates sequences of possible future outcomes before executing actions, enabling smarter, faster strategy selection.
The broader push for compact, responsive AI architectures is visible across the industry. Alongside CompACT, platforms like Xiaomi MiMo opening a 0.101M token recharge system before API billing signal that developers are racing to reduce data and compute costs at every layer. Less visual data does not have to mean worse decisions.
 Saad Ullah
Saad Ullah


