 Peter Smith
Peter Smith

⬤ Claude Opus 4.6 now supports a 1 million token context window, letting it process entire codebases, long document sets, or extended multi-session workflows in a single request. No chunking, no summarization workarounds, just one very large prompt. The competitive context is shifting fast: Gemini 3.1 Pro jumped 13 points above Gemini 3 Pro on the ArenaAI leaderboard, signaling just how heated the long-context race has become.
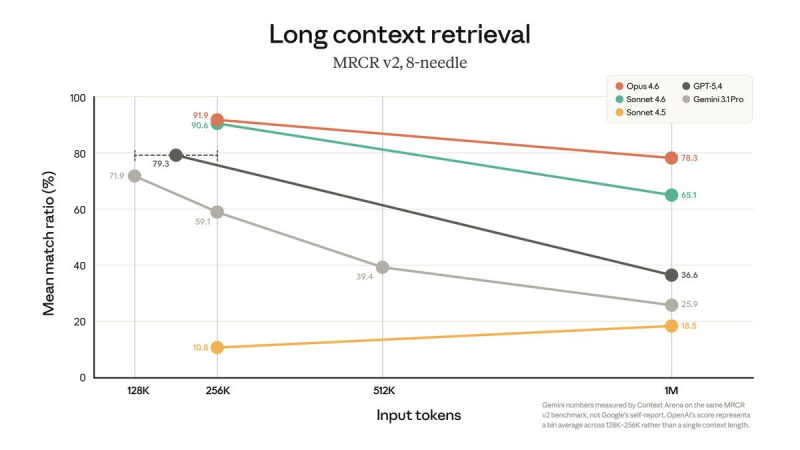
⬤ On the MRCR v2 long-context retrieval benchmark, the model hit a 78.3% mean match ratio at 1M tokens. The test is unforgiving: it hides specific facts across a million tokens and demands the exact correct answer, not a close one. That puts Claude Opus 4.6 at the top of the frontier model rankings at this context scale.
⬤ The jump from earlier versions is stark. Previous iterations of the same system scored around 18.5% on MRCR v2, illustrating just how hard long-context retrieval actually is. The comparison chart also shows Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro all trailing off as input size grows. Not every rival is keeping pace on accuracy either: Gemini 3 Pro shows lower error rates but still trails Claude Sonnet 4.5 at 15%.
⬤ The broader industry is moving fast on multiple fronts at once. Context length, retrieval accuracy, and reasoning depth are all advancing in parallel. A clear example: OpenAI rolled out GPT-5.4 Thinking with 92.8% on GPQA Diamond, raising the bar across the board and pushing every lab to respond.
 Peter Smith
Peter Smith


