 Artem Voloskovets
Artem Voloskovets

⬤ Early benchmark data from analytics platform PostHog shows that Gemini 3 Pro delivers a meaningful drop in tool error rates compared to Gemini 2.5 Pro. The chart stacks up four major AI models, revealing that while Gemini 3 Pro improves on what came before, it still doesn't beat Claude Sonnet 4.5, which posts the lowest error rate in the entire dataset.
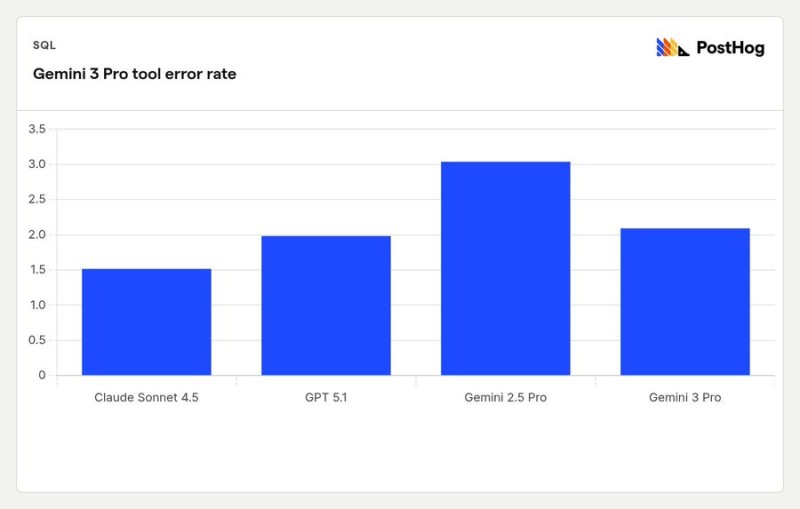
⬤ Looking at the numbers, Claude Sonnet 4.5 clocks in at roughly 1.5 percent error rate, making it the strongest performer in the bunch. GPT 5.1 sits around 2 percent, while Gemini 3 Pro lands slightly above that in the same range. The biggest gap shows up between Gemini 3 Pro and Gemini 2.5 Pro, with the older version hitting nearly 3 percent errors. These results back up the claim that Gemini 3 Pro brings improved tool-execution stability compared to earlier Gemini versions.
⬤ The bar chart also makes it clear that performance differences across leading AI models are still pretty significant. Even with Gemini 3 Pro's improvements, Claude Sonnet 4.5 keeps a clear lead in reliability, cementing its spot as the most consistent model in this benchmark. GPT 5.1 seems to land in the middle ground, performing well but not quite matching Claude Sonnet 4.5. The drop in tool errors from Gemini 2.5 Pro to Gemini 3 Pro points to a real upgrade in execution capability within the Gemini lineup.
⬤ This matters because tool-use reliability has become critical for how AI systems plug into automation workflows and enterprise apps. Error rate differences shape expectations around model robustness and practical deployment risks, ultimately defining the competitive landscape as model releases speed up and benchmarks expand.
 Artem Voloskovets
Artem Voloskovets


