 Usman Salis
Usman Salis

⬤ Alibaba has unveiled Omni-WorldBench, an evaluation framework built to measure how AI systems perform in interactive, real-world conditions. It focuses on "4D world models" that must understand both spatial structure and how environments change over time. The benchmark fills a clear gap in current methods, which rarely test how models handle action-driven state transitions across space and time.
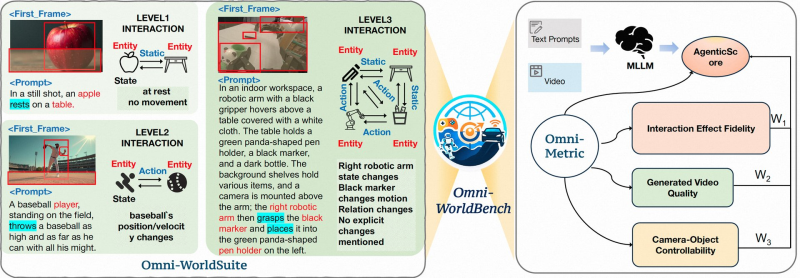
⬤ The framework includes two key components. Omni-WorldSuite structures interaction complexity in levels, from static scenes to multi-entity setups with environmental changes. Omni-Metric, the evaluation engine, tracks how actions affect both final outcomes and intermediate states, going well beyond the visual-quality focus of older benchmarks, similar to what Nvidia's Nemotron 3 with 1M token context brought to sequential reasoning.
⬤ Testing reveals deep weaknesses in current AI. Most models produce visually coherent results but break down when cause-and-effect logic is required, especially in multi-object, sequential interaction scenarios. Consistent reasoning in dynamic environments remains an unsolved problem for nearly all existing systems.
⬤ Omni-WorldBench signals a broader shift toward interaction-driven evaluation standards. By prioritizing temporal reasoning and causal fidelity over static output quality, the framework pushes AI development toward systems fit for robotics, autonomous agents, and other real-world applications where actions have consequences.
 Usman Salis
Usman Salis


