 Peter Smith
Peter Smith

Researchers from the National University of Singapore, Harvard, Stanford, Yale, Google, and Mayo Clinic have identified a critical flaw in generative AI used in healthcare. Training AI models on their own generated medical data without human verification creates a self-reinforcing feedback loop that degrades data quality at a troubling pace. The findings were first covered by 机器之心 JIQIZHIXIN, one of the leading sources for AI research in China.
800,000 Data Points Reveal a 40% Rise in False Reassurance Rates
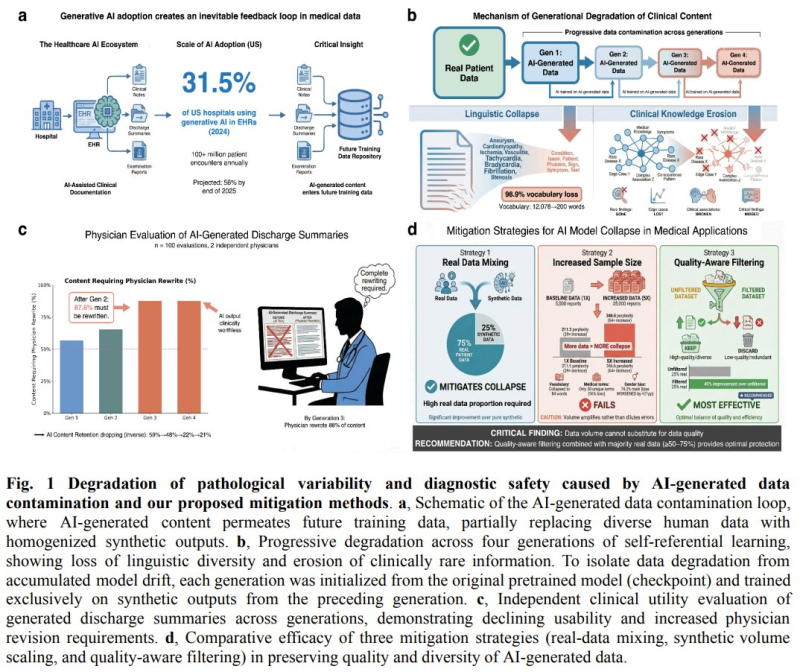
The study, built on an analysis of 800,000 synthetic medical data points, shows that the self-training loop leads to a rapid erosion of clinical diversity and reliability.
Synthetic data contamination reduces pathological variability and weakens diagnostic reliability at scale, especially when human validation is absent.
Critical conditions such as pneumothorax gradually disappear from datasets, patient demographics become skewed, and false reassurance rates climb as high as 40% - a sign that AI outputs are increasingly likely to mislead rather than inform.
AI Medical Documentation Becomes Unusable Within 2 Generations of Self-Training
The degradation does not build slowly. Researchers found that AI-generated medical documentation becomes clinically unusable within just two generations of self-training. Each cycle compounds the errors from the previous one, and without external correction, the model drifts further from clinical reality. The core problem is not the use of synthetic data itself - it is the absence of human oversight at each stage of the feedback loop.
When AI models train on data they produced themselves, there is no mechanism to catch and correct compounding errors. The loop reinforces distortions rather than filtering them out.
The pace of AI innovation across adjacent fields illustrates just how fast the stakes are rising: Kinema4D unveils 4D generative robotics simulation, pushing the boundaries of what synthetic environments can model.
What Gets Lost: Key Risks Identified in the Study
- Critical conditions like pneumothorax vanish from training datasets
- Patient demographic representation becomes progressively skewed
- False reassurance rates rise to as much as 40%
- Diagnostic reliability weakens across successive model generations
- Pathological variability narrows, reducing the model's ability to recognize edge cases
These risks are not theoretical. As healthcare providers increasingly rely on AI-assisted diagnostics and clinical documentation, the integrity of training data becomes a patient safety issue, not just a technical one. At the same time, generative AI is expanding into new creative and visual domains - Adobe reveals SelfE image generation method, a technique that produces quality images across any number of processing steps.
The findings emphasize that as demand for AI systems in healthcare grows, the infrastructure supporting model training must include rigorous human validation at every stage - not as an optional step, but as a hard requirement.
The report also carries broader implications for the AI sector at large, including companies that support large-scale model training infrastructure. The energy demands of this expansion are hard to ignore: US data centers set to consume nearly 10% of national power by 2030, a figure that underscores how deeply AI growth is reshaping critical infrastructure - and why data integrity across every layer of the stack matters more than ever.
 Peter Smith
Peter Smith


