 Marina Lyubimova
Marina Lyubimova

⬤ A new breakdown of data pipelines in machine learning systems shows that data quality can't be an afterthought anymore. The architecture diagram that's making the rounds demonstrates how validation needs to happen early—before training and inference pipelines even kick in. This isn't just theory; it's how production-grade systems supporting both traditional ML and LLM workflows are actually built.
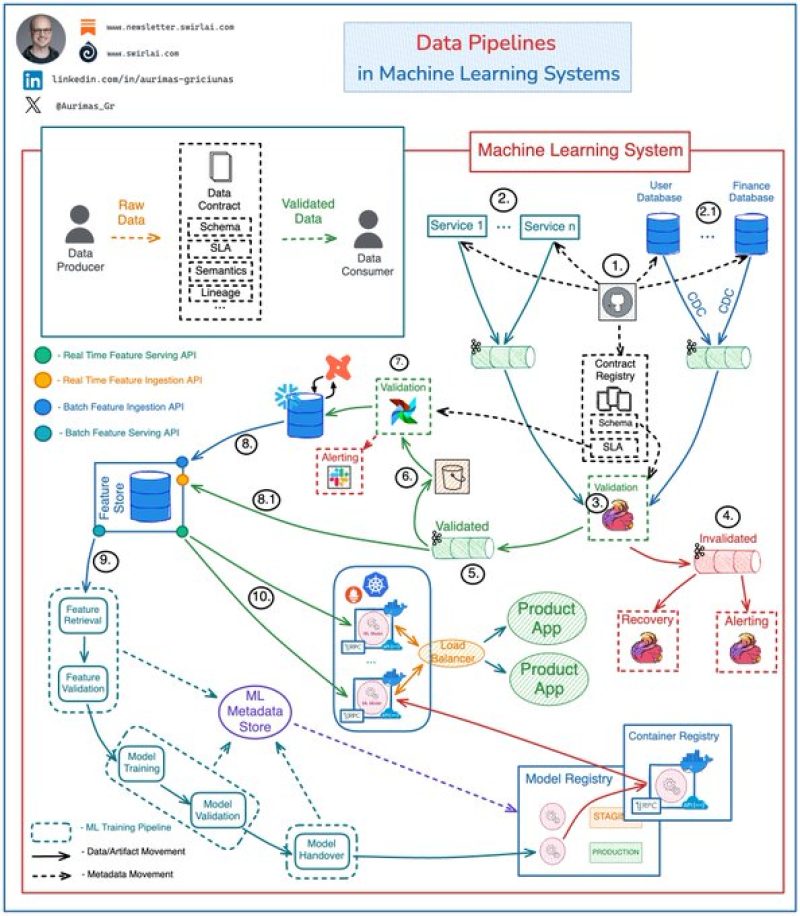
⬤ Here's how it works: raw data from application services—think IoT fleets, website tracking, you name it—streams into Kafka topics. Schema changes get version-controlled through a centralized data contract registry that defines schemas, SLAs, and validation rules. Stream-processing apps like Flink consume that raw data and validate it against these contracts. Failed data? Goes straight to dead-letter topics. Clean data? Moves forward as validated streams ready for the next stage.
⬤ Once validated, data lands in object storage where scheduled SLA checks run before anything hits the data warehouse for transformation and modeling. From there, curated datasets flow into a feature store for engineering work. The system also handles real-time feature ingestion directly from validated streams, though enforcing SLA checks at that speed gets tricky fast.

⬤ Most ML failures don't come from bad models—they come from bad data. Schema drift, contract violations, inconsistent features—these silent killers can wreck production systems. By baking in schema enforcement and governance at the data lake level, teams cut down on those risks dramatically. As ML and LLM systems become mission-critical for more applications, well-governed data pipelines aren't a nice-to-have anymore. They're the foundation everything else depends on.
 Marina Lyubimova
Marina Lyubimova


