 Usman Salis
Usman Salis

The AI landscape just witnessed a significant shift as Anthropic's latest model climbs to the pinnacle of search-weighted evaluations. In a competitive field where performance margins are razor-thin, Claude Opus 4.6 has distinguished itself by demonstrating superior search-grounded reasoning capabilities. The achievement marks a notable milestone for Anthropic as it positions itself against tech giants in the race for AI dominance.
Claude Opus 4.6 Dominates Search Arena Rankings
Claude Opus 4.6 has claimed the number one position on the Search Arena leaderboard, according to recent data from Arena.ai. The model achieved an impressive score of 1255, establishing a clear lead over its closest competitors. Right behind it, Grok-4.20-beta1 secured second place with approximately 1225 points, while GPT-5.2-search and Gemini-3-flash-grounding followed closely in the 1218-1219 range. The tight clustering of scores at the top reveals just how competitive the frontier model landscape has become.
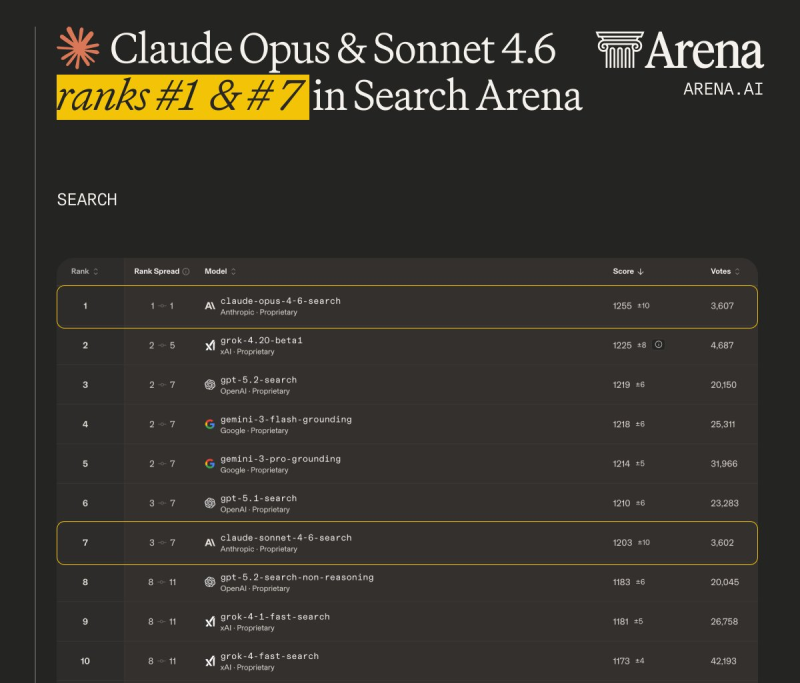
Anthropic placed a second model in the top ten as well. Claude Sonnet 4.6 landed at rank seven with a score of 1203, demonstrating that the company's model family consistently performs across different capability tiers. The Search Arena format specifically tests search-grounded reasoning and retrieval accuracy, areas where Claude's architecture appears particularly strong.
The ranking image provided shows Claude Opus 4.6 maintaining notable leads across multiple evaluation categories including Text, Code, and Search.
The tight clustering of scores at the top reveals just how competitive the frontier model landscape has become.
This wasn't just a benchmark victory either. The model has proven its capabilities in practical applications, recently generating a 10,000-line video editing application that showcased its real-world coding abilities.
How Claude Stacks Up Against Competition in AI Search
The competitive dynamics extend beyond simple leaderboard positions. Market perception and actual usage patterns have been shifting notably. Recent analysis showed that Grok-4 achieved 361% ROI as ChatGPT usage dropped from 80 to 20, indicating that user preferences are actively evolving across platforms.
Meanwhile, rival systems continue pushing their own boundaries. Google recently announced that Gemini 3 Deep Think hit 846 on ARC-AGI2, demonstrating strength in reasoning tasks. These parallel achievements highlight the intense competition driving innovation across major AI laboratories.
Claude Opus 4.6's sustained leadership across public benchmarks could significantly influence enterprise deployment decisions and ecosystem integrations as organizations evaluate which models best meet their specific needs in this rapidly evolving landscape.
 Usman Salis
Usman Salis


