 Victoria Bazir
Victoria Bazir

⬤ AI compute efficiency has been climbing at a pace few expected. Training efficiency has improved several-fold every year - even without any fundamental shifts in core architectures or algorithms. That's a striking finding, especially given the broader backdrop: OpenAI's $20B revenue milestone and 19 GW compute capacity in 2025 point to just how much infrastructure is now underpinning modern AI development.
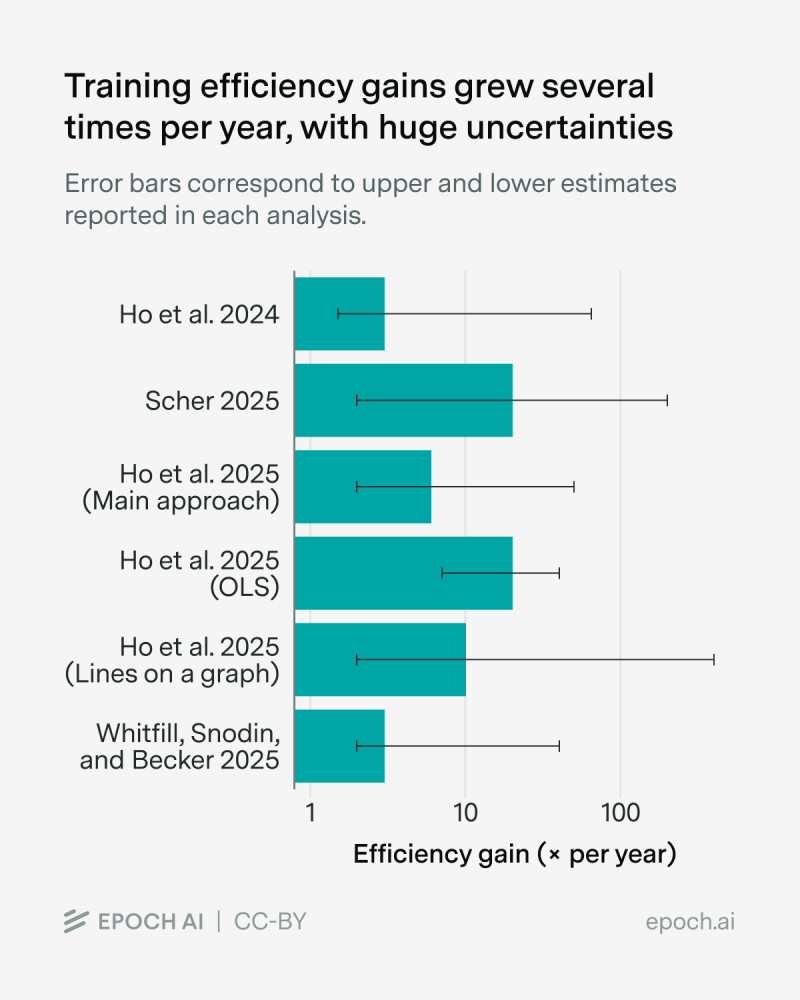
⬤ The data tells an interesting story. Efficiency estimates from Scher 2025 center around a roughly 10x per year gain, though the error bars stretch considerably higher depending on the methodology used. Ho et al.'s 2025 figures show central estimates ranging between 3x and 8x annually. These numbers carry real geopolitical weight, especially as concerns grow about China distilling AI models to narrow the technology gap with the West.
⬤ What makes these gains particularly notable is that they've happened quietly - no dramatic architectural overhauls, no paradigm-shifting breakthroughs visible from the outside. Efficiency appears to be driven by smarter training routines, better data handling, and hardware that simply does more with less. A good example: Rubin GPUs delivering 100x training efficiency gains over Hopper - a hardware leap that amplifies every algorithmic improvement built on top of it.
⬤ The economic implications are hard to ignore. When you need dramatically less compute to hit the same capability benchmarks, model development timelines get shorter, infrastructure strategies shift, and the barrier to entry drops. Uncertainty around the exact magnitude of annual gains remains real - but the direction is consistent. AI capability is scaling in ways that go well beyond just throwing more hardware at the problem.
 Victoria Bazir
Victoria Bazir


