 Saad Ullah
Saad Ullah

⬤ Martian, a research team with former engineers from DeepMind, Anthropic, and Meta, just launched Code Review Bench v0 - the first independent benchmark specifically designed to measure how well AI tools actually catch bugs during code reviews. The system tests tools both in controlled environments and tracks whether developers actually fix the issues flagged in real projects. "We're seeing massive growth in AI coding tools, with Gemini leads GenAI traffic growth with 19% jump in January 2026 showing how quickly adoption is accelerating," notes the research team.
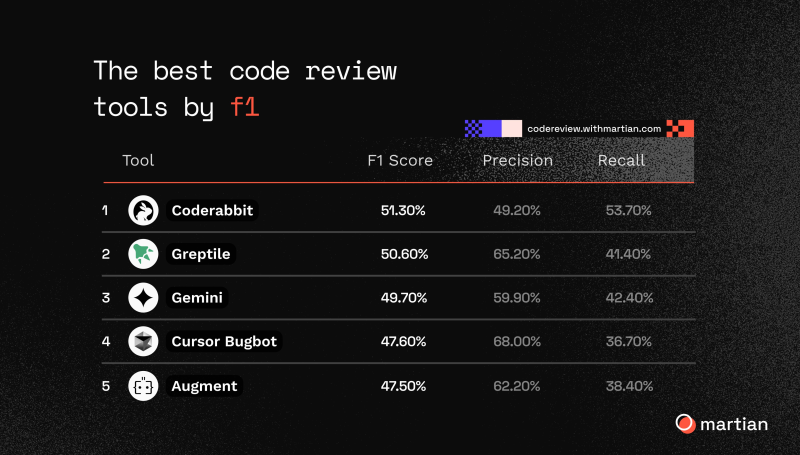
⬤ The rankings show CodeRabbit on top with 51.30% F1 score, Greptile close behind at 50.60%, and Gemini taking third at 49.70%. Cursor Bugbot and Augment round out the top five performers. Interestingly, precision and recall vary wildly - Cursor Bugbot nails precision at 68.00% but only catches 36.70% of bugs overall. No tool detected more than 63% of known bugs, highlighting the same verification challenges we're seeing across AI systems, similar to advances in DualWorld AI powers Fourier GR3 with 2-system humanlike whole-body motion control.
⬤ What makes this benchmark different is its dual approach: offline testing with identical pull requests for fair comparison, plus online tracking of actual open-source repositories to see when developers really act on the flagged bugs. This combination catches the gap between how tools perform in labs versus messy real-world coding. It's part of a bigger shift in how we evaluate AI tools, echoing discussions around Grok Code set to match Claude's performance by April 2025.
⬤ The launch highlights a crucial point: traditional static benchmarks don't capture how developers actually work. As AI coding assistants become standard across both enterprise and open-source projects, evaluation systems that include real behavioral data will likely become the new standard for comparing tool performance.
 Saad Ullah
Saad Ullah


