 Usman Salis
Usman Salis

Most AI agents learn by watching and copying. They study expert behavior, replicate the patterns, and hope those patterns hold in new situations. But mimicry has a ceiling - and a team of researchers thinks they've found a way past it.
What Is Agentic Critical Training and Why Does It Matter?
The framework is called Agentic Critical Training (ACT), and its core idea is deceptively simple: instead of showing a model what to do, show it two options and reward it for picking the better one.
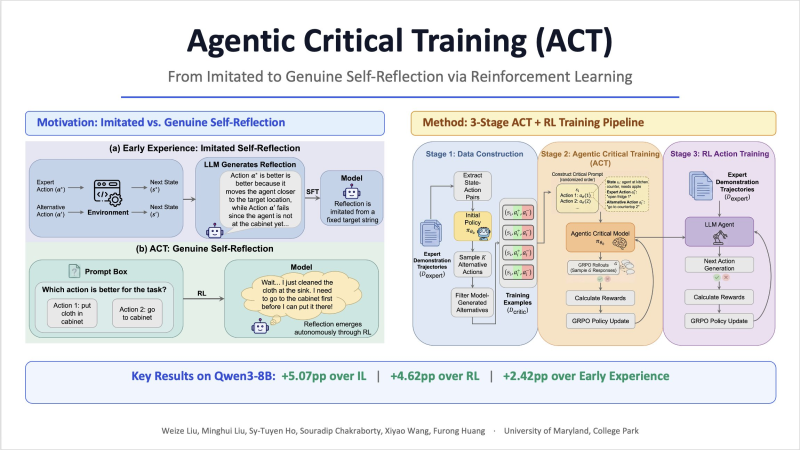
This shifts the training objective from imitation to judgment - teaching agents to reason about action quality rather than just reproduce sequences. The broader significance of this becomes clear when you consider research showing that 2 diverse AI agents beat 16 identical ones - variety in reasoning, not volume, drives better outcomes.
5.07-Point Gain Over Imitation Learning in Benchmark Tests
The ACT pipeline runs in three stages. First, expert trajectories are broken into state-action pairs and alternative actions are generated. The model then learns to distinguish the better action via reinforcement learning rewards. Finally, the refined model is trained to produce the correct action during actual task execution. Benchmark results show an average improvement of 5.07 points over imitation learning and 4.62 points over reinforcement learning baselines - numbers that matter even more as training efficiency becomes a competitive edge, as demonstrated by Qwen3-VL-8B's 75% reduction in training compute.
The implications reach beyond benchmark numbers. By building internal reasoning about decision quality, ACT-trained agents could become more reliable in complex, open-ended environments - less likely to fail when situations don't match their training data. As agent platforms grow more commercially accessible, illustrated by moves like Xiaomi MiMo opening its token recharge system before API billing, the demand for agents that can reason - not just react - is only going to grow.
 Usman Salis
Usman Salis


