 Saad Ullah
Saad Ullah

⬤ Let's be real—most AI models just describe what they see in videos. Video-Thinker actually thinks through them. Built by researchers from Xiaohongshu and Monash University, this model doesn't rely on external tools to understand video content. Instead, it mimics how humans process visual information, actively reasoning through what's happening on screen rather than just labeling objects and actions.
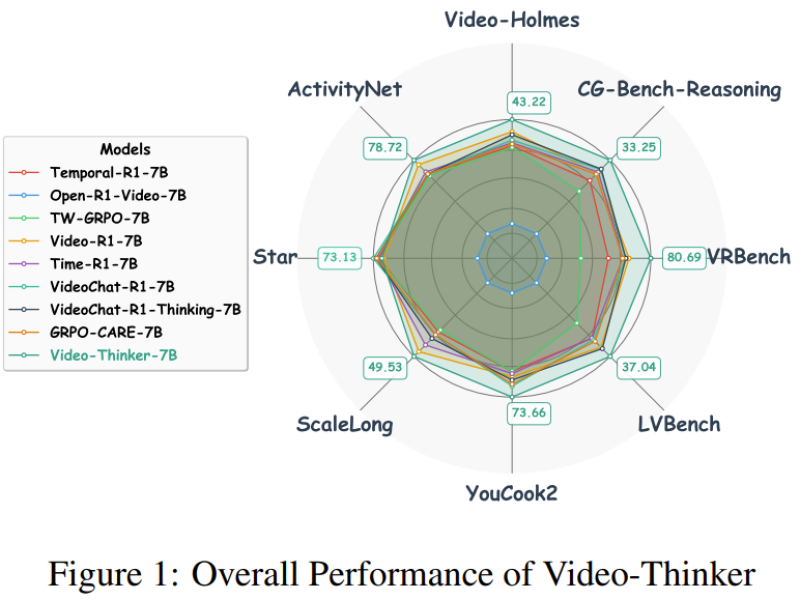
⬤ Here's what makes it different: Video-Thinker generates its own descriptive captions and spatial cues internally as it reasons. Perception and reasoning aren't separated—they're integrated. This lets the model track actions, objects, and timing across longer video sequences without losing the plot, fixing a major weakness in earlier video AI systems.
⬤ The numbers back it up. Video-Thinker dominates every other 7B-sized model across benchmarks like Video-Holmes, ActivityNet, YouCook2, LVBench, VRBench, Star, and ScaleLong. It beats Video-R1, Time-R1, GRPO variants, and other video-language models consistently. The takeaway? Reinforcement learning-powered internal reasoning delivers serious performance gains without bloating the model size.

⬤ Why this matters: video reasoning is becoming critical for robotics, autonomous systems, content analysis, and embodied AI. Video-Thinker proves you can hit state-of-the-art results at the 7B scale just by building smarter internal reasoning structures. As AI shifts from labeling what it sees to actually reasoning about it, this approach could reshape how future multimodal models get trained and deployed in real-world applications.
 Saad Ullah
Saad Ullah


