 Marina Lyubimova
Marina Lyubimova

⬤ A new way to teach AI about complex tasks looks at what really changes in each step, not at abstract labels. The Task Step State framework ties learning to real, visible changes - like ingredients blending or objects shifting - rather than to vague, high level wording.
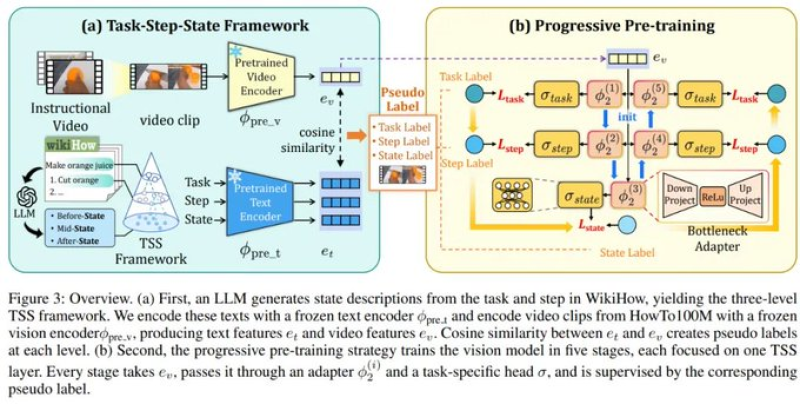
⬤ The method begins with a language model that writes a short description of how each step looks before, during and after - the text comes from sources like WikiHow. Each video clip and its matching text are turned into separate codes - clips plus texts that look alike are paired. The outcome is a three layer chain that links the whole task to its steps and then to the exact change of state within each step.
⬤ Training moves upward through the layers. The model first learns to spot the task then the step then the small state change inside the step. The researchers state: “state-level supervision is the key factor driving those improvements.” In other words, the AI must see how objects physically change - that alone lifts performance.

⬤ The numbers show the gain - on both COIN besides CrossTask, the framework sets new records for task recognition, step identification and next-step prediction. When the researchers delete state tracking, scores fall sharply - the drop proves that watching how actions alter the world is essential for real understanding.
 Marina Lyubimova
Marina Lyubimova


