 Eseandre Mordi
Eseandre Mordi

⬤ OpenAI just grabbed the top spot in a widely circulated AI intelligence comparison after GPT-5.2 Pro posted the highest score on the Mensa Norway benchmark. The ranking puts GPT-5.2 Pro ahead of a crowded field of competing models, all tested using the same Mensa Norway quiz focused on pure reasoning ability rather than creative output.
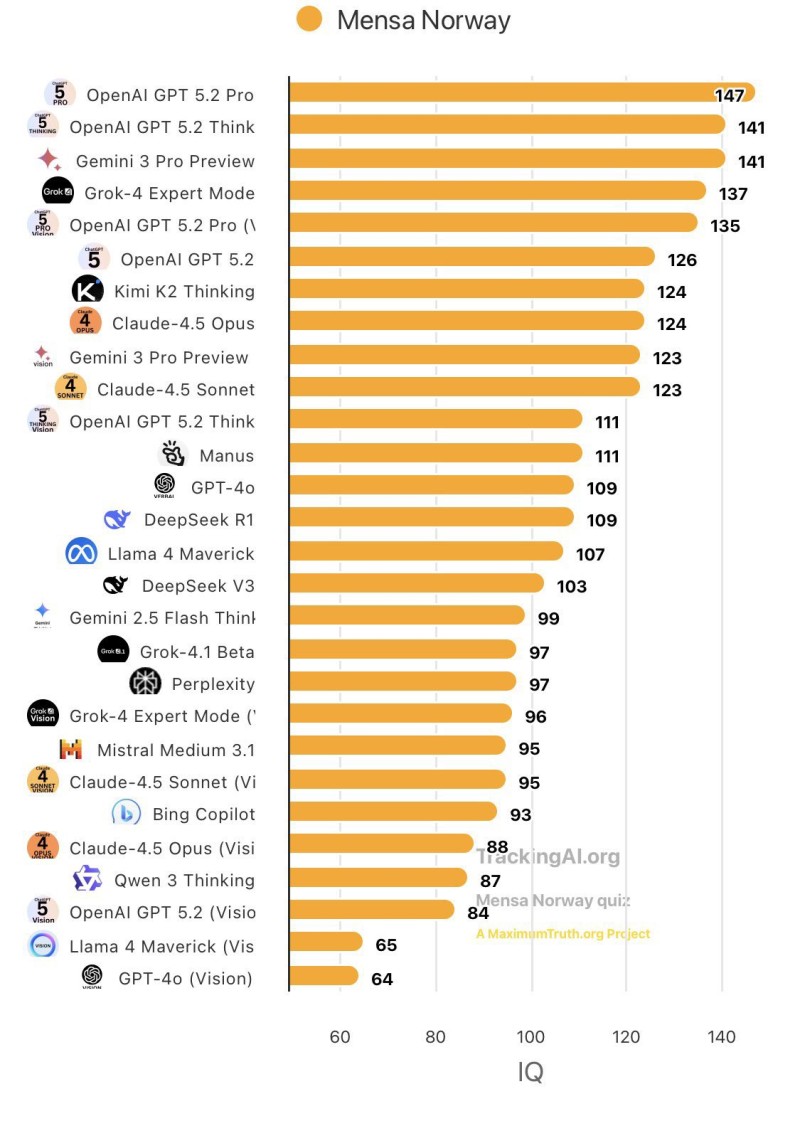
⬤ GPT-5.2 Pro hit 147 on the test—the highest mark in the entire dataset. Right behind it came OpenAI GPT-5.2 Think and Gemini 3 Pro Preview, both landing at 141, with Grok-4 Expert Mode following at 137. Several other GPT-5.2 variants filled out the upper ranks, showing that OpenAI's latest model lineup performs consistently well on IQ-style reasoning challenges.
⬤ The full ranking reveals a noticeable performance gap across the AI landscape. Mid-tier models like Claude-4.5 Opus, Kimi K2 Thinking, DeepSeek R1, and Llama 4 Maverick cluster together in the middle range, while vision-focused versions tend to score lower. The spread suggests reasoning-specialized models are pulling ahead more decisively at the top end.

⬤ Benchmark results like this carry real weight in enterprise and research circles. Strong performance on standardized reasoning tests shapes how platforms are viewed in terms of capability and reliability, influencing competitive positioning and future development priorities. With GPT-5.2 Pro leading the Mensa Norway ranking, OpenAI reinforces its edge in reasoning-focused evaluations.
 Eseandre Mordi
Eseandre Mordi


