 Eseandre Mordi
Eseandre Mordi

⬤ SimpleBench just dropped new results that caught everyone off guard—GPT-5.2 managed only 45.8% on this reasoning-focused benchmark. That's way lower than what most people expected, especially since SimpleBench tests actual common-sense thinking rather than just regurgitating memorized answers.
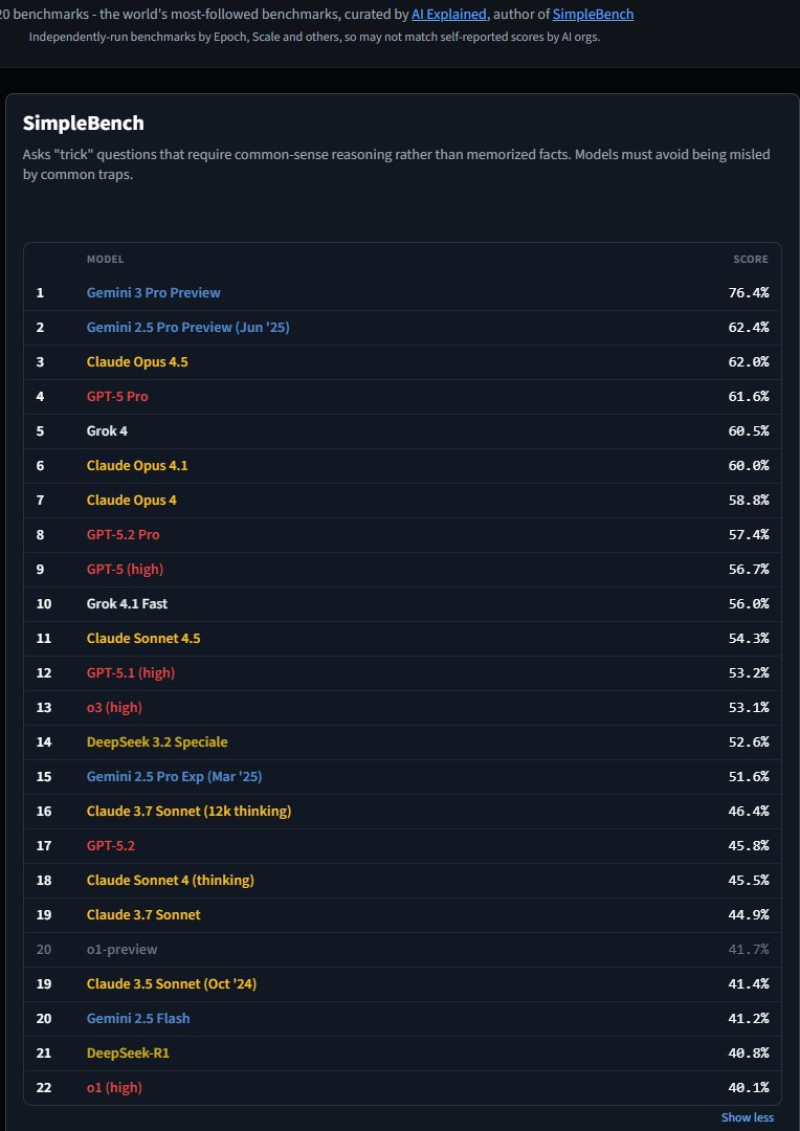
⬤ The leaderboard tells quite a story. Gemini 3 Pro Preview absolutely crushed it with 76.4%, while Gemini 2.5 Pro Preview grabbed second place at 62.4%. Claude Opus 4.5 came in close behind at 62.0%. Here's what really stings for GPT-5.2—even GPT-5 Pro scored 61.6%, Grok 4 hit 60.5%, and Claude Opus 4.1 reached 60.0%. So we're looking at a newer model that's somehow performing worse than its predecessors and competitors when it comes to navigating tricky reasoning scenarios.
⬤ Things get even more interesting when you look at the full picture. GPT-5.2 landed behind GPT-5 (high) at 56.7%, GPT-5.1 (high) at 53.2%, and even DeepSeek 3.2 Speciale at 52.6%. Multiple Claude versions scattered between 44% and 62% also outperformed or matched it. Remember, SimpleBench specifically throws "trick" questions at these models—the kind that need flexible thinking and can't be fooled by misleading hints. For a model hyped up for its reasoning chops, scoring 45.8% is definitely raising eyebrows.

⬤ What this really shows is how tight the race has become in AI reasoning capabilities. Every percentage point matters now, and GPT-5.2's SimpleBench showing proves that being "good enough" in general doesn't cut it anymore when specialized reasoning is on the table. Sure, GPT-5.2 still handles most everyday tasks just fine, but this benchmark exposes where it struggles. With everyone racing to release their next big thing, you can bet future models will be judged hard on these exact types of reasoning tests.
 Eseandre Mordi
Eseandre Mordi


