 Usman Salis
Usman Salis

Building a few lines of code is one thing - creating an entire software repository from scratch is another beast entirely. A new benchmark is putting that theory to the test, and even the most advanced AI models are coming up short.
ByteDance, along with M-A-P, 2077AI, and several top Chinese universities, just rolled out NL2Repo-Bench - a challenging new test designed to see if cutting-edge coding agents like GPT-5 can actually build complete software repositories on their own. The benchmark doesn't mess around: it asks AI systems to take a basic natural language description and turn it into a fully functional, installable Python library starting from nothing. We're talking real-world development here - long-term planning, consistent architecture, dependency juggling, and execution across the entire lifecycle, not just isolated code snippets.
How the Benchmark Actually Works
The whole process runs through four distinct phases: picking the repository, writing project documentation, setting up the environment, and then verification with refinement. Models have to reverse engineer specifications, pull out APIs, configure runtime environments, build test images, and pass both static and dynamic validation checks.
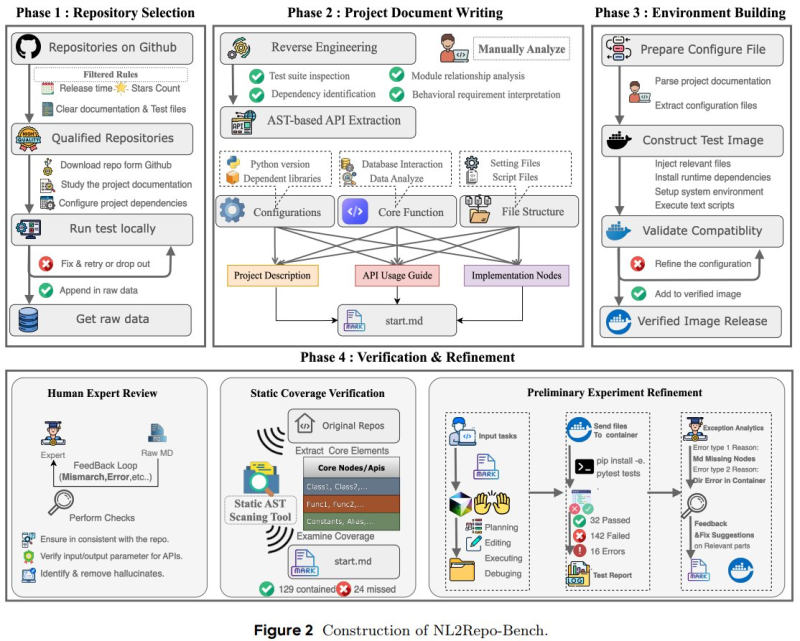
Even with recent breakthroughs in handling massive contexts - like QwenLongL15 handles 4 million tokens, matches GPT-5 on long-context tests - keeping everything coherent across hundreds of interconnected files is proving to be a real headache.
Where Models Are Falling Short
The results aren't pretty. Even the best models barely cracked 40% pass rates, failing most of the automated tests thrown at them. The biggest problems? Long-term dependency tracking, keeping structural consistency across the entire repository, and managing multi-stage configurations. And here's the kicker - while infrastructure keeps scaling up, including efforts like XAI rolls out Grok batch API processing 25MB workloads, simply throwing more computing power at the problem isn't fixing these fundamental reasoning gaps.
What This Means for AI Development
NL2Repo-Bench's launch really highlights how the industry is shifting focus toward measuring practical autonomy in AI-powered software development. Sure, we're seeing platform improvements like Lovable adds Claude Opus-46 with 21% performance boost, but those sub-40% pass rates make it crystal clear: fully autonomous, long-horizon software engineering is still a puzzle the AI world hasn't solved yet.
 Usman Salis
Usman Salis


