 Marina Lyubimova
Marina Lyubimova

⬤ QwenLong-L1.5 has arrived as a long-context reasoning model built to tackle massive documents and extreme memory demands. The model processes up to 4 million tokens in a single pass, roughly the same as reading 100 novels simultaneously. This marks a major leap forward in how AI handles extended context.
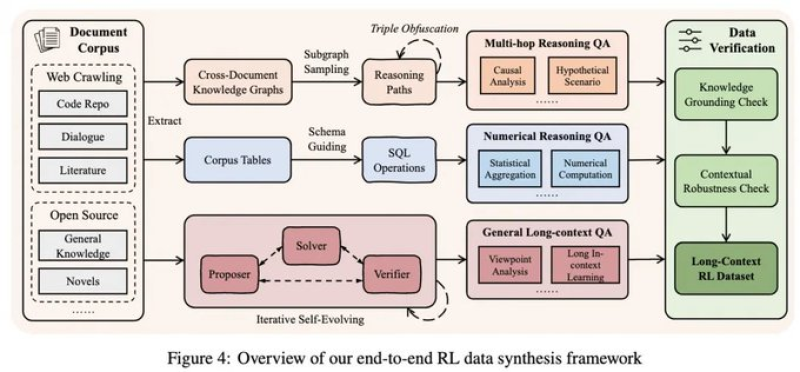
⬤ The secret sauce is a new post-training methodology focused on long-context reasoning and memory management. The training process generates complex, multi-step reasoning questions straight from source documents, uses stabilized training to cut down bias, and integrates a memory system that lets the model work with sequences beyond its native context window. The framework combines cross-document knowledge graphs, multi-hop reasoning, numerical analysis, and long-context question answering—all verified for robustness through reinforcement learning.

⬤ On benchmarks, QwenLong-L1.5 matches the performance of GPT-5 and Gemini-2.5-Pro on long-context reasoning tasks. The model also showed nearly a 10-point improvement over its own baseline, proving the post-training strategy delivered real gains. Beyond long-context tests, it excels at scientific reasoning and extended dialogue, both requiring sustained coherence and memory across lengthy interactions.
 Marina Lyubimova
Marina Lyubimova


