 Eseandre Mordi
Eseandre Mordi

⬤ xAI's Grok-4.20-Beta has taken the top position on the Search Arena leaderboard for search and retrieval tasks. The model ranks first when Style Control is enabled and second when it's off. Built on roughly 500 billion parameters, it is optimized for web search and information synthesis, placing it ahead of systems from several major AI labs. The milestone was highlighted in Grok 4.20 Beta tops Search Arena, edges out larger AI models.
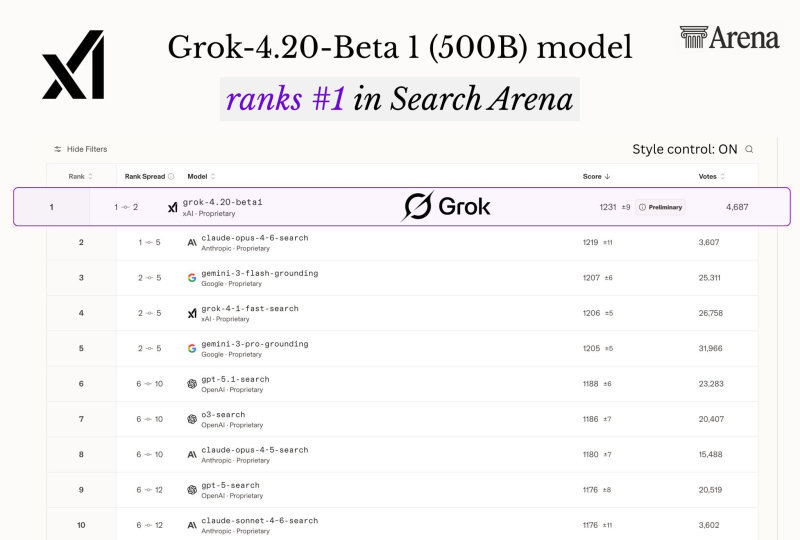
⬤ On the Search Arena leaderboard, Grok-4.20-Beta scored approximately 1,231 points (±9 confidence interval) across around 4,687 votes. Its closest rival, Claude-Opus-4-6-search from Anthropic, scored around 1,219, with Google's Gemini-3-flash-grounding close behind at roughly 1,207. The benchmark works by showing users side-by-side responses to real queries and collecting votes to determine which model performs better in real-world search scenarios.
Architectural optimization and retrieval design can matter more than raw parameter count when it comes to real-world search performance.
⬤ Despite its 500B size, Grok-4.20-Beta reportedly outperformed models estimated to contain between one and five trillion parameters. The result shows that architectural efficiency and retrieval design can matter more than sheer scale. This kind of progress has fueled broader debates, similar to those sparked by the GPT-5 vs GPT-4 chart and the heated debate about racing toward AGI.
⬤ The Search Arena results underscore how fast competition among AI labs is moving on search-focused benchmarks. Public leaderboards now offer real-time comparisons across xAI, Google, OpenAI, and Anthropic, evaluated by actual users rather than static tests. The same dynamic is playing out elsewhere, as seen when OpenAI's GPT-5.1 hit 1,401 ELO to claim #1 on DesignArena, reflecting the broader race to improve AI reasoning, search accuracy, and usability.
 Eseandre Mordi
Eseandre Mordi


