 Eseandre Mordi
Eseandre Mordi

⬤ ModelScope just dropped benchmark results showing their DASD-4B-Thinking model crushing it across major reasoning tests. The model hit the top spots on AIME24, AIME25, LiveCodeBench v5, and GPQA—beating out both open-weights and open-data competitors in head-to-head comparisons.
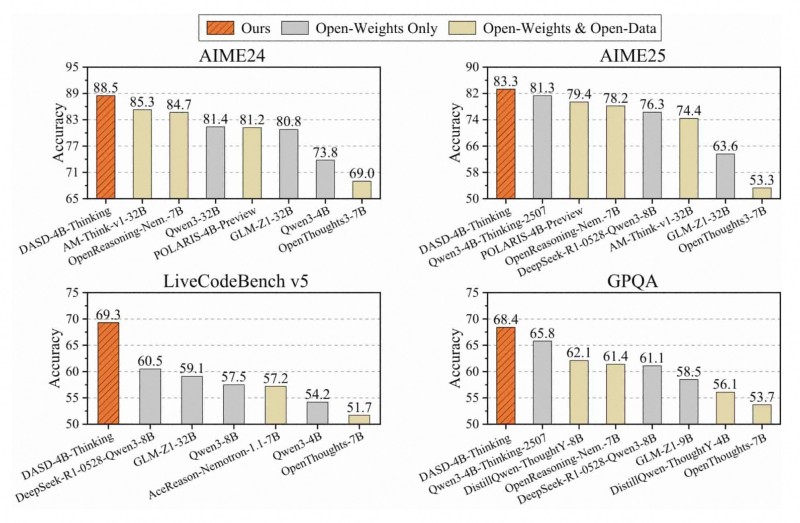
⬤ The numbers tell the story: 88.5% accuracy on AIME24 and 83.3% on AIME25, with LiveCodeBench v5 coming in at 69.3% and GPQA at 68.4%. In every single category, DASD-4B-Thinking outperformed alternatives, including larger models and other reasoning-focused open-source systems.
⬤ What's behind the performance? ModelScope points to their Distribution-Aligned Sequence Distillation pipeline, which tackles two key problems in reasoning distillation: distribution mismatch between teacher and student outputs, and exposure bias during generation. The approach syncs training distributions with inference-time behavior, boosting reliability without needing massive model sizes.

⬤ Since launch, DASD-4B-Thinking has blown past 10,000 downloads on Hugging Face, and ModelScope released the Superior-Reasoning-SFT-gpt-oss-120b dataset with 435,000 high-quality reasoning samples. The combination of strong benchmarks and open resources shows real momentum in making top-tier reasoning models accessible to everyone.
 Eseandre Mordi
Eseandre Mordi


