 Usman Salis
Usman Salis

A quiet but crucial rivalry is unfolding at the cutting edge of artificial intelligence. Recent data from the ARC AGI Challenge reveals that OpenAI's internal model from December 2024 still holds the top benchmark score—outperforming even GPT-5 Pro and Anthropic's latest Claude Sonnet 4.5. The chart, sourced from ARC Prize, illustrates just how close the two AI giants have become in developing systems capable of reasoning and generalizing beyond typical large language model behavior.
OpenAI's December 2024 Model Still Unmatched
The chart tracks the ARC-AGI-1 benchmark, which evaluates AI reasoning and abstraction skills. Trader Peter Gostev recently highlighted this revealing data in a tweet, drawing attention to the competitive landscape between the two companies.
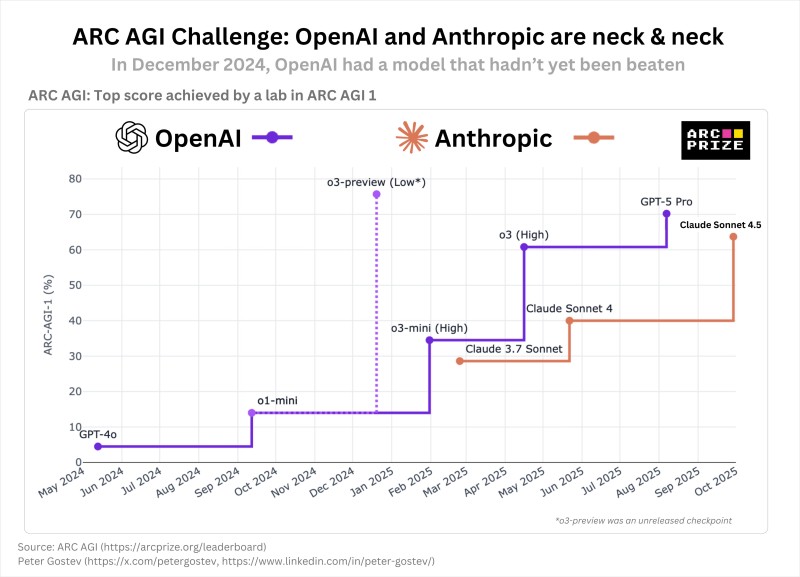
Key findings include:
- OpenAI's o3-preview (Low*), created in December 2024, achieved around 75–78%, marking the highest recorded performance on ARC AGI 1
- Despite multiple releases since, including GPT-5 Pro in mid-2025, no public OpenAI model has surpassed that score
- Anthropic's Claude Sonnet 4.5, released in late 2025, now trails narrowly behind at roughly 70–72%
This means OpenAI had effectively reached its top reasoning benchmark nearly a year before today's leading models—reinforcing the notion that part of its progress remains behind closed doors.
Anthropic's Rapid Catch-Up
Anthropic's improvement curve tells a story of consistent acceleration. Claude 3.7 Sonnet debuted in March 2025 just below OpenAI's o3-mini line. By June 2025, Claude 4 jumped closer to OpenAI's o3 (High) level. Then in October 2025, Claude 4.5 nearly closed the gap with GPT-5 Pro. Within six months, Anthropic's ARC AGI score rose by roughly 10 points, bringing its models within striking distance of OpenAI's best.
Understanding the ARC AGI Benchmark
The ARC (Abstraction and Reasoning Corpus) benchmark—developed by Google researcher François Chollet—measures how well AI systems solve unseen problems that require logical reasoning and pattern discovery, not memorization. It's considered one of the most reliable indicators of proto-AGI capabilities, testing reasoning generalization, abstract thinking, and zero-shot problem solving. Can the AI handle new logic puzzles it wasn't trained on? Does it understand relationships and transformations beyond text? Can it infer the rules from limited examples? Unlike typical benchmarks such as MMLU or GSM8K, ARC AGI focuses on adaptability—the kind of intelligence humans use to learn something entirely new.
 Usman Salis
Usman Salis


