 Peter Smith
Peter Smith

⬤ OpenAI's GPT-5.2 xhigh just bombed a major physics test, landing at 0% on the CritPt benchmark - a specialized evaluation that measures real theoretical physics reasoning. GPT-5.2 xhigh wasn't alone in this struggle, joining several other advanced AI models that couldn't crack this particularly challenging assessment.
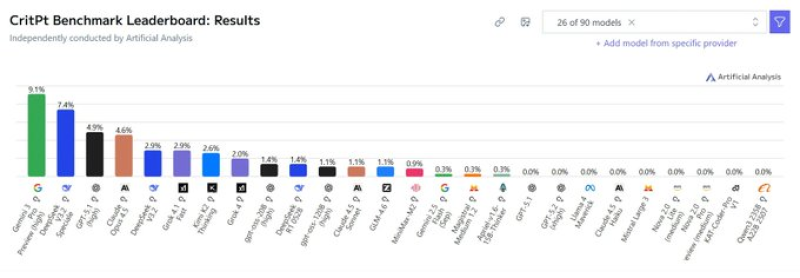
⬤ CritPt isn't your typical AI benchmark. It's specifically built to separate genuine expert-level physics reasoning from basic pattern matching. The current leaderboard shows just how brutal this test really is - even the top performer, Gemini 3 Pro, only managed 9.1%. Most models barely register any score at all.
⬤ The benchmark doesn't mess around when it comes to grading. It demands formal reasoning, mathematical precision, and airtight logic. Make an incomplete derivation or slip up on your reasoning? You're penalized heavily. This strict approach reveals weaknesses that typically fly under the radar in broader AI evaluations.
⬤ What this really shows is there's still a massive gap between AI systems crushing general tasks and actually handling specialized scientific work. Sure, GPT-5.2 xhigh performs well across many language and reasoning challenges, but when it comes to advanced theoretical physics, we're clearly not there yet. As competition heats up between AI labs, benchmarks like CritPt are becoming crucial reality checks for measuring where genuine progress still needs to happen.
 Peter Smith
Peter Smith


