 Saad Ullah
Saad Ullah

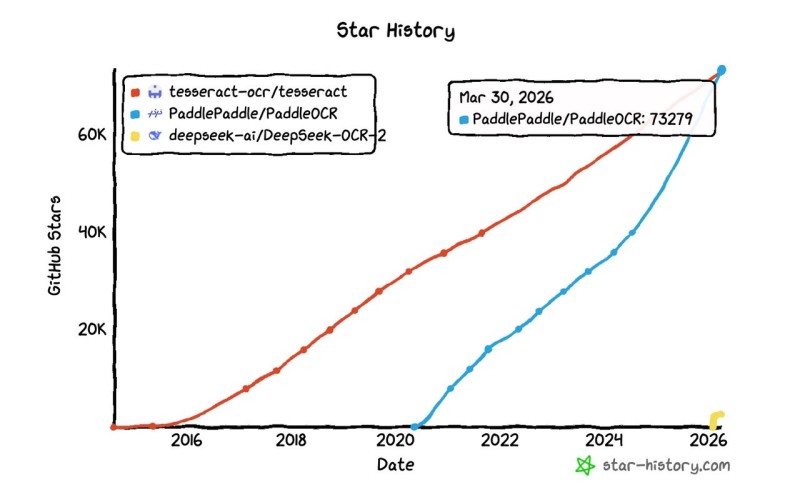
The open-source AI landscape just hit a notable inflection point. PaddleOCR has crossed 73,000 stars on GitHub, overtaking Tesseract - a system that defined document recognition standards for more than 40 years. As Parul Gautam noted, the milestone reflects something larger than a popularity contest: it signals where developers are placing their bets on the future of OCR technology.
The numbers tell a clear story. PaddleOCR's GitHub trajectory has been steep since around 2020, accelerating sharply from 2022 onward to reach approximately 73,300 stars by March 2026. Tesseract's growth, while steady over the past decade, never matched that pace. The gap between traditional and AI-native tools is now visible in plain data.
Why PaddleOCR Is Winning the OCR Race in 2026
The appeal goes well beyond star counts. PaddleOCR handles full document parsing - tables, formulas, and mixed layouts - across more than 110 languages.
Built on ERNIE foundation models, it operates less like a recognition tool and more like a complete document intelligence system. That distinction matters to developers building pipelines that need to process complex, real-world documents at scale.
PaddleOCR's support for over 110 languages and complex document structures positions it as a complete document intelligence platform rather than just an OCR engine.
This evolution mirrors patterns seen across the broader AI ecosystem. Much like Baidu's SAMA video AI tops open-source benchmarks, model-driven approaches are consistently outperforming rule-based and legacy methods once the training data and architecture mature enough.
How AI-Native Tools Are Displacing 40-Year-Old Standards
The shift from Tesseract to PaddleOCR is part of a wider pattern in open-source AI: newer, model-driven frameworks are pushing out legacy tools not through incremental improvement, but through fundamentally different architectural approaches. Efficiency gains at the system level are compounding rapidly. The trend is visible in adjacent areas as well - as covered in AI ecosystem sees Nanobot cut agent code by 99%, reductions in complexity and overhead are increasingly becoming a key driver of developer adoption.
The milestone underscores a broader transformation where scalability, multilingual support, and integrated AI capabilities are reshaping what developers expect from document processing tools.
For Tesseract, the loss of top-ranked status is not a failure of the project - it is a reflection of how much the baseline expectations for OCR tools have changed. What once required specialized pipelines and manual post-processing is now expected out of the box. PaddleOCR delivers that, and the GitHub numbers confirm developers have noticed.
 Saad Ullah
Saad Ullah


