 Saad Ullah
Saad Ullah

⬤ Baidu has introduced Qianfan-OCR, an end-to-end vision-language model built on roughly 4 billion parameters that merges document recognition and layout analysis into a single architecture. A built-in "Layout-as-Thought" mechanism makes the model reason about page structure before producing any output, rather than treating recognition and formatting as two separate jobs.
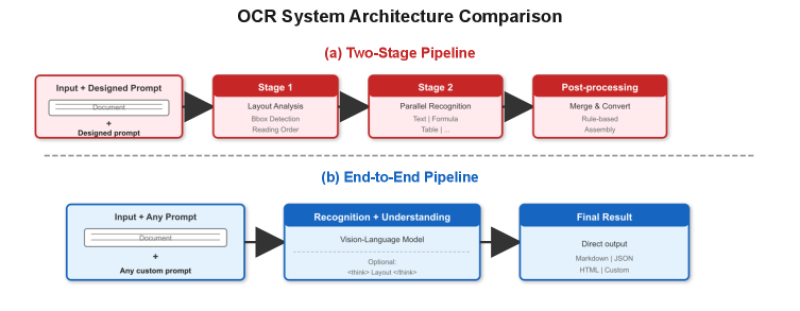
⬤ Standard OCR pipelines chain together discrete stages - layout detection, text extraction, post-processing. Qianfan-OCR collapses all of that into one forward pass, writing structured results directly. Fewer handoffs means fewer failure points, and it mirrors the trajectory Mistral OCR 3 has taken to hit 95% accuracy across five document types - a signal that end-to-end design is quickly becoming the industry default.
⬤ Baidu's key technical bet is "think tokens" - an internal pass that resolves bounding boxes, reading order, and layout logic before any output is committed. The advantage is sharpest on demanding content: tables, equations, dense multi-column text. In published tests the model scored 93.12 on OmniDocBench and 880 on OCRBench, finishing ahead of both Qwen3-VL-235B and Gemini 3.1 Pro.
⬤ Beating Gemini carries real weight. Gemini 3.1 Pro throughput dropped 46% to around 50 tokens per second on Google Vertex, yet it remains a benchmark-level multimodal competitor - which makes Baidu's margin on document tasks a more meaningful result than a simple score comparison would suggest.
⬤ Open-source pressure is mounting just as fast. Qwen3-VL 8B now leads its weight class on 75% less training compute than earlier versions - evidence that efficiency, not raw scale, is becoming the defining edge in multimodal document AI.
 Saad Ullah
Saad Ullah


