 Saad Ullah
Saad Ullah

⬤ A new AI framework built for scientific research evaluation has shown it can spot high-impact papers before they go mainstream. Researchers introduced two systems, Scientific Judge and Scientific Thinker, trained on roughly 696,000 to 700,000 citation-based paper pairs. The model learns which papers end up being influential by studying patterns in how science cites itself over time. This kind of domain-specific AI reasoning is part of a wider push seen in fields like AI humanoid robots entering daily life.
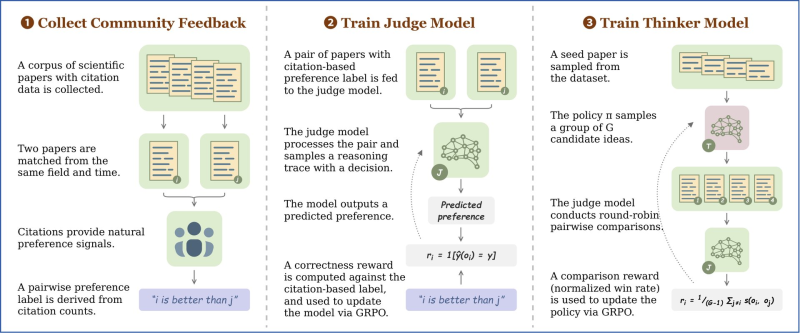
⬤ Citation counts do the heavy lifting here. Papers from similar fields and time windows are paired together, and those citation numbers become preference labels, essentially teaching the model which work carried more weight. The result is Scientific Judge, a system that predicts relative research impact and, according to the study, outperformsboth GPT-5.2 and Gemini 3 Pro at forecasting which papers will matter most. For context on just how fast these benchmarks are moving, GPT-5.2 is already 5 years ahead of expert predictions on coding benchmarks.
⬤ The Scientific Thinker takes things a step further. Built on top of the judge model, it uses reinforcement learning from community feedback to actually generate new research ideas. Candidate ideas are sampled, scored through pairwise comparisons, and refined through iterative training, pushing outputs toward higher-impact directions. It is a closed loop of evaluation and generation that mirrors how real scientific intuition develops, and it raises new questions about AI black swan risk modeling as these systems grow more autonomous.
⬤ This points to a broader shift in AI, from systems that just execute tasks to ones that evaluate and propose knowledge. Science, it turns out, is just the next domain AI is learning to have taste in. If models can already beat GPT-5.2 and Gemini 3 Pro at predicting which research will matter, the question of who, or what, sets the agenda for discovery starts to feel a lot more urgent.
 Saad Ullah
Saad Ullah


