 Saad Ullah
Saad Ullah

Two recent developments have quietly changed the conversation around how artificial intelligence could scale in the coming years. Both suggest that training massive AI models across continents, rather than concentrating everything in single enormous facilities, might actually work.
A New Approach to AI Infrastructure
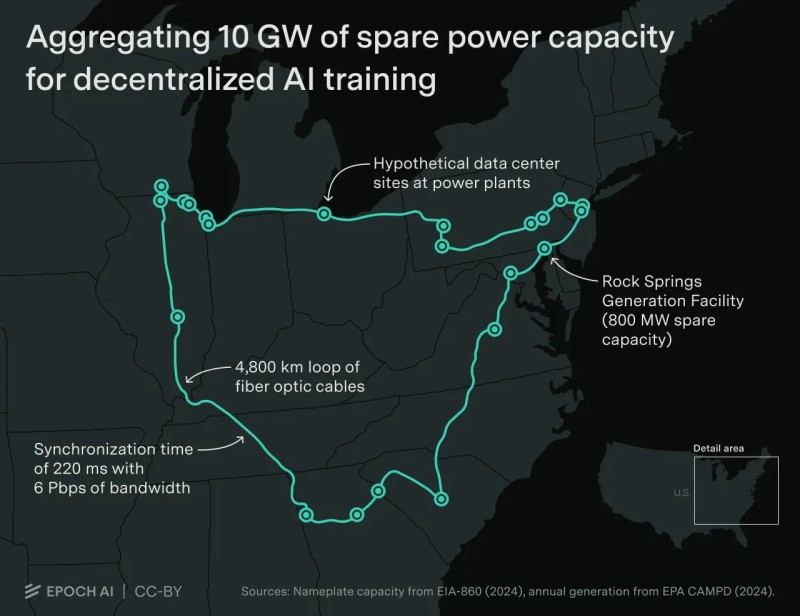
Shanu Mathew recently highlighted two significant breakthroughs that caught the attention of the tech community. The first comes from Epoch AI, which mapped out how roughly 10 gigawatts of spare power capacity scattered across the United States could be networked together for decentralized AI training.
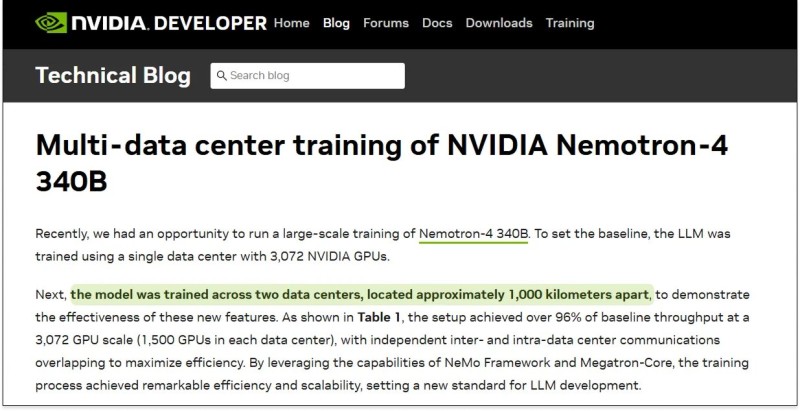
The second is NVIDIA's demonstration that its Nemotron-4 340B model can be trained across data centers separated by 1,000 kilometers without meaningful performance degradation.
What makes these findings particularly noteworthy is that they challenge a long-held assumption. For years, distributed AI training seemed impractical because of latency issues and power constraints. These two pieces of work suggest that's no longer the case.
Mapping Spare Power Capacity
Epoch AI's research presents a visualization of a 4,800-kilometer fiber loop connecting 23 power plant sites across the eastern United States. Together, these sites could aggregate 10 gigawatts of spare capacity for AI workloads. One example highlighted in their work is the Rock Springs Generation Facility in Maryland, which alone has 800 megawatts of unused capacity sitting idle.
The proposed network would synchronize data at around 220 milliseconds latency using 6 petabits per second of bandwidth. That's fast enough to support real-time parameter updates between data centers during training. The key insight here is straightforward: instead of building a single 2-gigawatt campus from scratch, you could tap into dozens of smaller sites that already have power generation and fiber infrastructure in place. According to Epoch AI's researchers, such distributed training runs are achievable without major increases in either training time or cost, as long as interconnect bandwidth stays in the multi-petabit range.
NVIDIA's Real-World Validation
NVIDIA recently provided experimental proof that this approach actually works. In their official developer blog, the company confirmed that Nemotron-4 340B, a 340-billion-parameter language model, was successfully trained across two data centers roughly 1,000 kilometers apart. Using their NeMo Framework and Megatron-Core, they achieved over 96 percent of baseline throughput, essentially matching the efficiency of single-site training. The setup involved around 3,072 GPUs split evenly between the two locations. Despite the long-distance communication, performance remained stable throughout. This marks the first verified case of multi-region AI training operating at near-full efficiency, proving that latency and bandwidth challenges can be managed through smart parallelization and overlapping computation.
Why Power Limits Matter Now
Today's most advanced AI systems require energy on the scale of small power plants. Centralized megasites increasingly run into problems: grid congestion, permitting delays, and regional energy shortages. Decentralized training offers a practical alternative. It lets companies balance grid demand by tapping underutilized regional capacity, reduces permitting friction when building new infrastructure, and takes advantage of existing fiber routes and renewable energy sites. The result is something like a virtual AI supercomputer that spans thousands of kilometers but operates as one synchronized system.
From Single Sites to Neural Networks
The images from Epoch AI and NVIDIA's technical blog tell a consistent story. The future of AI infrastructure looks increasingly distributed, energy-aware, and geographically networked. Instead of one massive facility consuming gigawatts of power in a single location, companies could build clusters of smaller data centers linked by high-speed fiber, each drawing on local spare capacity. This approach scales compute more sustainably while also improving resilience and reducing dependency on any single point of failure.
 Saad Ullah
Saad Ullah


