 Alex Dudov
Alex Dudov

⬤ OpenDataArena's arrived as a fresh research platform built to measure what datasets are actually worth when you're training AI models. The initiative flips the script—instead of just looking at model performance, it digs into the data that's feeding them. It's tackling a real gap in the AI world: we need fair, transparent ways to compare datasets, especially as training costs keep climbing and data volumes explode.
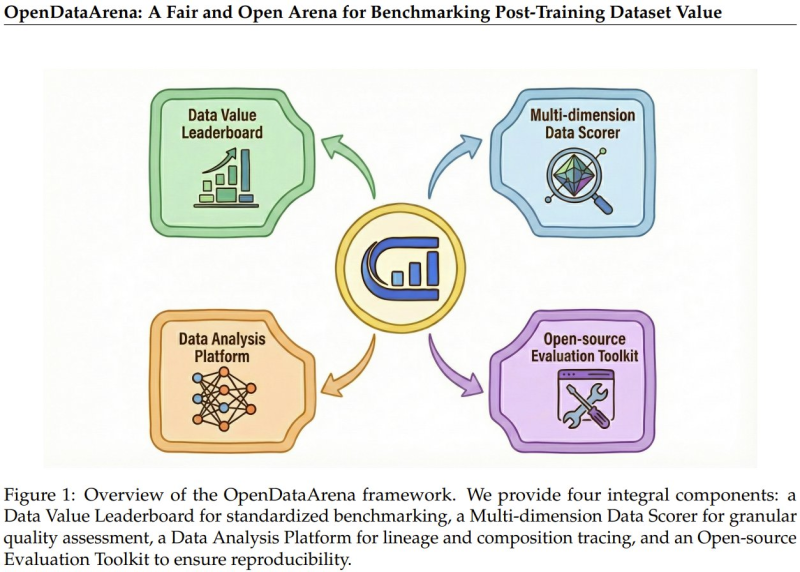
⬤ The platform runs on four connected pieces that work together. There's a Data Value Leaderboard for apples-to-apples comparison, a Multi-dimension Data Scorer that grades datasets across different quality measures, a Data Analysis Platform that tracks where data comes from and what it's made of, and an open-source Evaluation Toolkit so anyone can replicate the results. These tools let researchers break down datasets piece by piece instead of just checking if the final model works.
⬤ Here's what they've found so far: OpenDataArena's already chewed through analysis of over 120 datasets. Turns out bigger or more complex datasets don't automatically win—there are real trade-offs between complexity and actual performance. They've also spotted hidden redundancy in popular benchmarks by mapping out dataset relationships like a family tree, showing researchers where there's overlap and wasted effort in commonly recycled data.

⬤ Why does this matter? Because picking the right dataset is becoming just as critical as the model architecture itself. Training's expensive, and tools that can put a number on dataset value help teams make smarter calls about what data to curate, reuse, or optimize. OpenDataArena represents a bigger movement toward data-centric AI evaluation—giving researchers the info they need to allocate resources better and build future systems that are both more efficient and more transparent about what's under the hood.
 Alex Dudov
Alex Dudov


