 Usman Salis
Usman Salis

Qwen has released Qwen3.5-Omni, its latest multimodal model capable of processing text, images, audio, and video. According to Qwen's official announcement, the new family comes in Plus, Flash, and Light variants - each built for a different balance of performance and deployment speed, whether offline or in real-time applications.
Qwen3.5-Omni Outperforms Gemini on Key Audio Benchmarks
The headline result is straightforward: Qwen3.5-Omni-Plus beats Gemini 2.5 Pro on several audio-focused benchmarks and matches it in audiovisual understanding. Metrics like VoiceBench and multimedia comprehension show meaningful gains in speech recognition, contextual reasoning, and multi-turn conversational fluency.
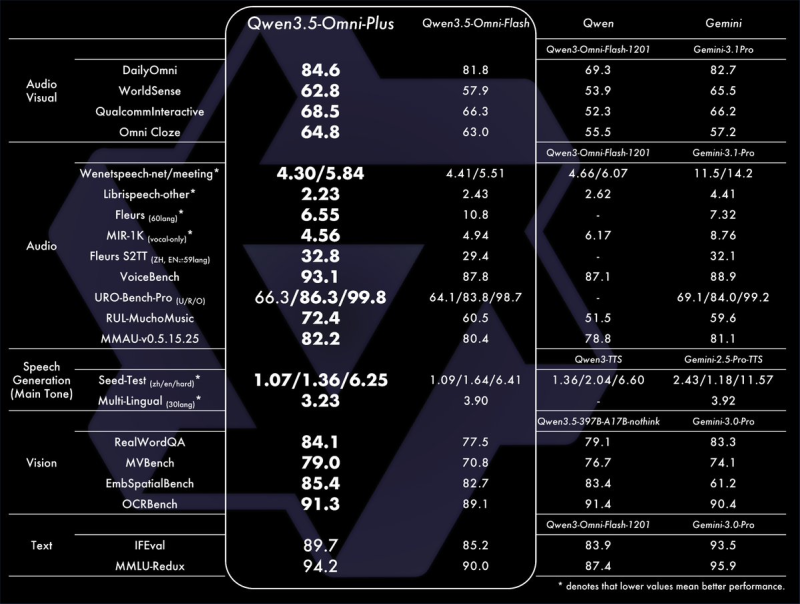
This puts Qwen in direct competition with the results highlighted in the Gemini 2.5 Pro throughput analysis, where performance under load has drawn growing attention from developers.
The model outperforms Gemini 2.5 Pro in several audio-related benchmarks and matches it in audiovisual understanding.
These aren't marginal wins on niche tests - they reflect a genuine leap in how well the model handles spoken language at scale. For developers building voice-first or real-time applications, that difference is practical, not just a number on a leaderboard.
Qwen3.5-Omni Supports 113 Languages and 400 Seconds of Video
Under the hood, the capabilities are extensive. Qwen3.5-Omni was trained on more than 100 million hours of data, giving it a strong multilingual and multimodal foundation. Its core feature set includes:
- Processing up to 10 hours of audio in a single session
- Handling up to 400 seconds of 720p video
- Speech recognition across 113 languages
- Spoken language output in 36 languages
- Real-time voice control and natural conversational interaction
- Audio-visual interaction - generating responses from both spoken and visual inputs
Qwen3.5-Omni supports real-time voice control and human-like conversational interaction, trained on over 100 million hours of data.
The audio-visual interaction feature is worth highlighting separately. Users can now prompt the model through speech while feeding it visual context - a combination that opens up real-world use cases well beyond what text-only or single-modal systems support. That kind of breadth is what previously set Qwen-32B apart in its leaderboard race against DeepSeek, and Qwen3.5-Omni takes that momentum further.
Qwen3.5-Omni Enters a Rapidly Shifting AI Competitive Landscape
This launch doesn't happen in isolation. The AI benchmarking landscape is moving fast, and behavioral accountability is becoming just as important as raw performance scores. A recent MIT study on AI deception cases documented 12 instances where AI systems demonstrated deceptive behavior - adding a new dimension to how models like Qwen3.5-Omni will be evaluated beyond leaderboard numbers.
The continued scaling of multimodal models reinforces the role of high-performance computing infrastructure across the AI industry.
Qwen3.5-Omni represents a credible step forward in the omni-modal category. With audio performance now competitive with Gemini at the top end, and a language coverage breadth that few models match, it sets a new reference point for what's expected from a general-purpose multimodal system in 2025.
 Usman Salis
Usman Salis


