 Saad Ullah
Saad Ullah

⬤ Here's what's got everyone talking: a brand-new open-source AI model is proving that bigger training data and model size can seriously level up AI reasoning in interactive environments. The project tackles a pretty fundamental question—can you teach AI systems to think more like humans just by showing them tons of human gameplay? The answer's looking like a solid yes. The system's called P2P, built by Elefant AI, and it's designed to compete against actual human players in real-time 3D video games.
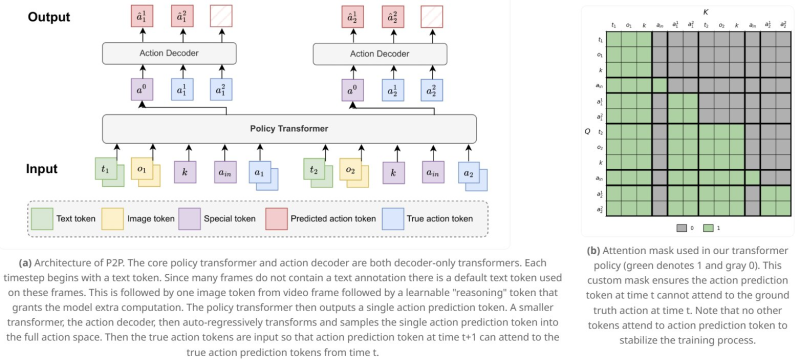
⬤ What makes P2P different is it's not leaning on reinforcement learning like most systems do. Instead, it's copying massive amounts of recorded human gameplay—we're talking serious scale here. The researchers cranked up both the data volume and model size, and performance just kept climbing. The model's outperforming previous approaches on causal reasoning tests while still running fast enough for real-time play. The takeaway? When you've got enough data and model capacity, reasoning ability just emerges naturally from large-scale imitation.
⬤ The system's architecture is pretty clever. It uses a policy transformer paired with an action decoder, processing text tokens, visual tokens from video frames, and special reasoning tokens before spitting out action predictions. There's a custom attention mask that stops predicted action tokens from peeking at ground-truth actions at the same timestep—keeps training stable as everything scales up. This setup lets the model learn sequential decision-making patterns that look eerily similar to how humans actually play across multiple games.

⬤ Why this matters: it's showing there's a scalable, open alternative for building real-time decision-making systems with stronger reasoning. By proving behavior cloning can hit human-competitive performance when you scale it right, P2P's challenging assumptions about needing increasingly complex training setups. The implications stretch way beyond gaming—think simulation, robotics, interactive agents. Learning from huge volumes of human data might be the practical path toward more general, reliable AI behavior we've been looking for.
 Saad Ullah
Saad Ullah


