 Saad Ullah
Saad Ullah

⬤ A team from Shanghai Jiao Tong University and Huawei has unveiled LoPA (Lookahead Parallel Decoding), a method that makes AI models generate text significantly faster. Instead of producing words one at a time like traditional systems, LoPA generates multiple tokens at once. The approach works as a plug-and-play solution that doesn't require retraining the original model.
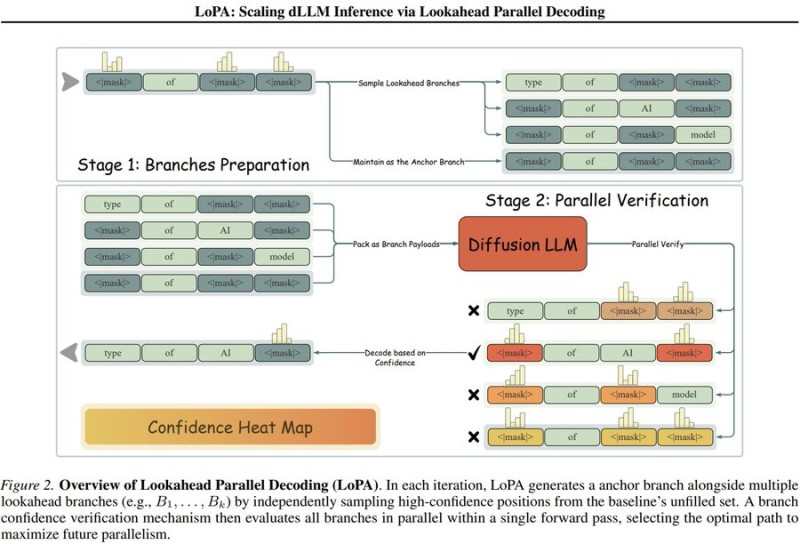
⬤ The system works through a two-stage process. First, it creates several lookahead branches from high-confidence token positions—essentially mapping out different ways the text could continue. Then it runs a parallel verification stage that evaluates all these possibilities simultaneously using a diffusion-based language model, picking the most promising path forward. This lets the model safely commit to multiple tokens in a single step rather than hesitating over each individual word.
⬤ When tested with the D2F-Dream diffusion language model, LoPA generated over 10 tokens per decoding step and hit speeds exceeding 1,070 tokens per second. The method showed strong performance improvements on the MBPP coding benchmark and GSM8K math problems compared to other top inference systems currently available.

⬤ This matters because inference speed has become a major bottleneck as AI models get bigger and more widely deployed. LoPA solves this without requiring extra training, which means lower computational costs and better hardware efficiency. It's a reminder that smart changes to how models decode text can unlock major performance gains—something that'll shape how we deploy large language models going forward.
 Saad Ullah
Saad Ullah


