 Sergey Diakov
Sergey Diakov

⬤ Grok-4 Expert Mode absolutely dominated recent AI IQ testing, pulling off scores that left the competition in the dust. The model hit 126 on a brand-new offline test and pushed that to 136 on the Mensa Norway benchmark. That's legitimately impressive when you're going head-to-head with heavyweights like Gemini 3 Pro. What makes this interesting is how well Grok-4 handles abstract reasoning and pattern recognition — the kind of stuff that separates decent AI from genuinely smart systems.
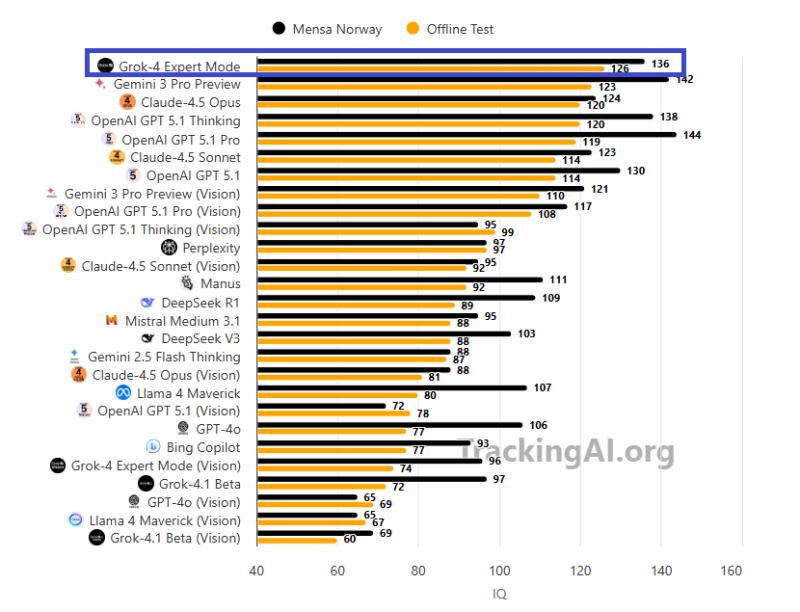
⬤ Here's the thing about these tests: Mensa Norway questions are floating around publicly, so there's always that question of whether models just memorized answers during training. That's why the offline test matters. These were fresh questions nobody's seen before, and Grok-4 still crushed it. That tells you the model isn't just regurgitating memorized patterns — it's actually figuring things out. When you stack it against Claude 4.5 Opus, OpenAI GPT-5.1 Thinking, Llama 4 Maverick, DeepSeek V3, and the Gemini lineup, Grok-4 comes out on top across both benchmarks.
⬤ The timing makes sense. We're in this wild sprint where every AI lab is racing to build models that don't just follow instructions but actually think through complex problems. Grok-4's performance shows xAI is serious about competing in the reasoning game — the kind of capability that matters for automation, robotics, and systems that need to make solid decisions without constant hand-holding.
⬤ Grok-4 Expert Mode hitting 136 on these tests signals real progress in AI reasoning benchmarks. As these systems keep evolving, the competition is shifting toward abstract logic, handling unfamiliar problems, and staying reliable when things get unpredictable. That's the stuff that'll determine which AI models actually make it into real-world applications versus which ones just look good on paper.
 Sergey Diakov
Sergey Diakov


