 Alex Dudov
Alex Dudov

xAI's Grok 4.20 has made a strong showing on one of AI's more demanding real-world benchmarks. The model placed second on the tau2-Bench Telecom leaderboard published by Artificial Analysis, scoring 96.5% accuracy and trailing only GLM-5, which topped the chart at 98.2%. The result puts Grok 4.20 ahead of Claude Opus 4.6, GPT-5.4 (xhigh), and Gemini 3.1 Pro - a notable benchmark win for the Elon Musk-backed AI lab.
What the tau2-Bench Telecom Test Actually Measures
The tau2-Bench benchmark tests agentic tool use in telecom-style environments. Models are evaluated on their ability to call external APIs, execute multi-step workflows, and complete complex operational tasks - the kind of work that real enterprise AI systems need to do reliably. It is a more practical test than many standard benchmarks, focused on whether a model can act, not just answer.
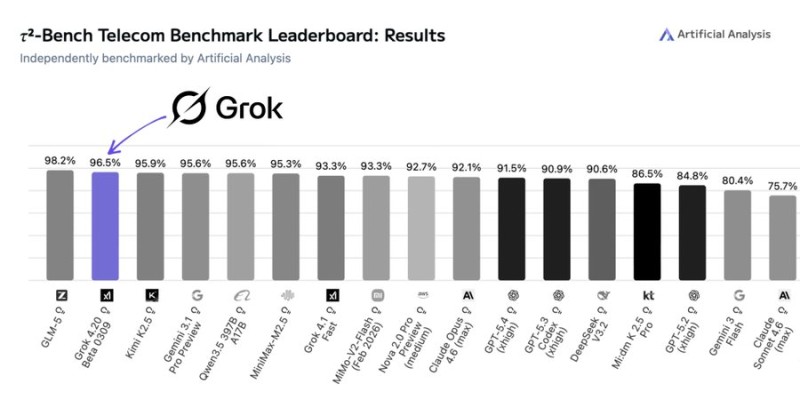
Grok 4.20 performed well against a competitive field that also included Qwen3.5, MiniMax-M2.5, DeepSeek V3.2, and Gemini Flash variants. The gap between first and second place was just 1.7 percentage points, making the result a close race rather than a runaway.
Grok 4.20 Builds Momentum Across Multiple Benchmarks
The telecom result is part of a broader performance run for the model. Developers working with the Grok 4.20 API, which launched with a 2-million token context window and three model variants, have noted its expanded capacity for large-context processing. Separately, Grok 4.20-Beta ranked #2 on Search Arena, placing it among the strongest AI search systems available today.
Beyond language tasks, the model has also shown an ability to operate in high-stakes decision environments. In a recent financial simulation, Grok 4.20 posted 12.11% returns in the Alpha Arena trading competition, demonstrating consistent performance across diverse benchmark categories.
The combined results point to a competitive model family gaining ground on multiple fronts as the AI industry shifts its focus toward autonomous, agent-based systems.
 Alex Dudov
Alex Dudov


