 Usman Salis
Usman Salis

For decades, a small cluster of mathematical problems has resisted every human attempt at proof. Now, a benchmark from Oxford researchers is putting AI to the same test, and the results are starting to shift. OpenAI's latest model has become the first system to produce verified progress on open problems that no human solver has cracked. GPT-5.4 Pro scored 92.8% on GPQA Diamond and is redefining what long-horizon AI reasoning looks like.
GPT-5.4 Pro Achieves 7% Solve Rate While Rivals Score 3%
Across the full 100-problem dataset, GPT-5.4 Pro recorded a 7% solve rate. Both Claude Opus 4.6 and Gemini 3.1 Pro each reached 3%. On Level 0 tasks, problems within human reach, GPT-5.4 Pro hit a 50% solve rate while competing models landed at 30%. The gap deepens at Levels 1-3, the genuinely unsolved territory: GPT-5.4 Pro produced two passing candidate solutions, while every other model, including the human baseline, returned zero.
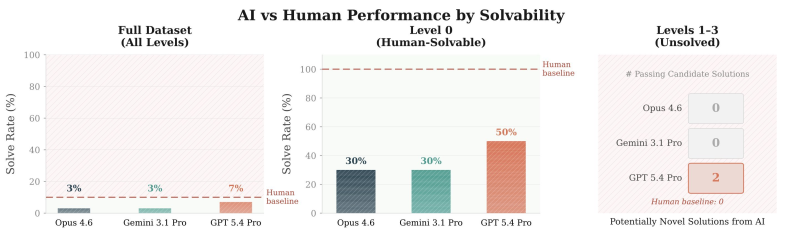
That result matters because Claude Opus 4.6 has also logged major math breakthroughs, including cracking Knuth's open problem, making the gap on this particular benchmark all the more telling.
Long-Horizon Reasoning Is Pushing AI Into Uncharted Mathematical Territory
Both advances came from extended computation sessions, not quick inference passes. On a Kakeya-type problem, GPT-5.4 Pro beat the AlphaEvolve baseline by 4.9%. On a Ramsey theory problem, it cut the diagonal bound constant by 2.7%. Neither result closes the underlying conjecture, but measurable progress on open mathematical problems is not routine, it is rare. The benchmark was built specifically to test this edge, pushing past standard evaluation sets where top models now routinely max out scores.
These findings reflect a wider divergence in how frontier models handle deep reasoning over long inference windows. Even strong performers are falling behind on tasks that require sustained, multi-step mathematical exploration. Gemini 3.1 Pro, which posted a 77.1% score on ARC-AGI2, still recorded zero solutions across all unsolved problem tiers. The ability to move the needle on genuinely open mathematics now appears to be its own category of capability.
 Usman Salis
Usman Salis


