 Usman Salis
Usman Salis

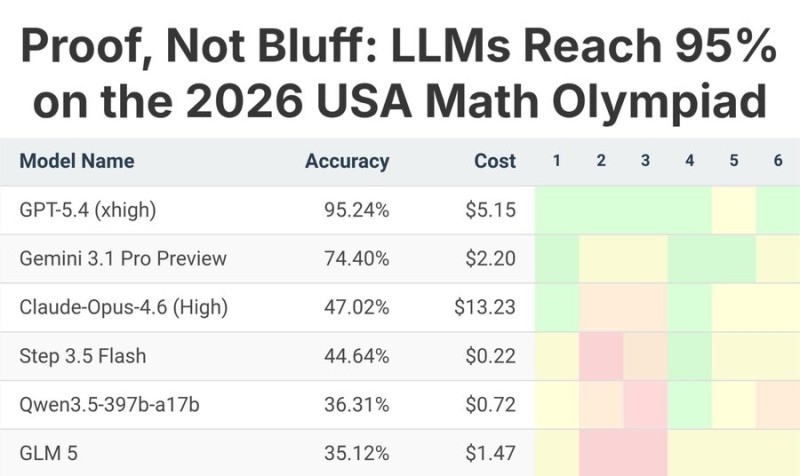
GPT-5.4 has set a new bar for AI math performance, reaching around 95% accuracy on the 2026 USA Math Olympiad benchmark. The results were shared by AlphaSignal AI, and they paint a striking picture of how quickly things have moved in just twelve months.
GPT-5.4 Leads the 2026 USAMO Results by a Wide Margin
The gap between GPT-5.4 and its nearest competitors is hard to ignore. At roughly 95.24%, it sits well ahead of the field - Gemini 3.1 Pro Preview comes in second at 74.40%, while Claude-Opus-4.6 records 47.02%. The rest of the pack - Step 3.5 Flash, Qwen3.5-397b-a17b, and GLM 5 - all land below the 50% mark.
AI systems are improving in advanced reasoning tasks at a pace that existing benchmarks can barely keep up with.
From Below 5% to 95% - What Changed in One Year on USAMO Math Problems
To put 2026's numbers in context, research evaluating USAMO 2025 problems found that models were scoring below 5% on the same class of problems. That's not a typo - the jump from near-zero to near-perfect happened within a single year. The 2025 results signaled limited reasoning ability at the time; the 2026 outcome tells a completely different story.
The acceleration in AI math capabilities over the past year has been sharper than most researchers expected.
What's driving the improvement is still being debated, but the data point itself is clear: something fundamental changed in how these models handle complex multi-step mathematical reasoning.
GPT-5.4 Is Nearing Saturation on This USAMO Benchmark
A 95% score is impressive, but it also raises a practical question - what comes next? AlphaSignal AI notes that errors still occur, so saturation is not complete. Still, when a model is approaching the ceiling of a benchmark this quickly, the field tends to respond by looking for harder benchmarks that can continue to separate top performers.
As top-tier models approach saturation on existing benchmarks, the question shifts to what comes next - and how we measure genuine progress in AI reasoning.
The broader implication is that the measurement tools themselves may need to evolve. USAMO-level math was considered a significant challenge just a year ago; today it looks like a baseline for the leading model. The pace of change is fast enough that performance comparisons can become outdated in months, not years.
 Usman Salis
Usman Salis


