 Marina Lyubimova
Marina Lyubimova

⬤ METR, an AI evaluation organization, reported that Claude Opus 4.6 has reached a 50% time horizon of about 14.5 hours on complex software tasks - the highest point estimate the group has published to date. The model's 95% confidence interval stretches from six hours to nearly 98 hours, a range that captures just how variable sustained AI work can be depending on task complexity. For comparison, earlier models like GPT-4o could handle tasks measured in minutes to roughly an hour on certain coding or classification work. The leap to multi-hour problem solving marks a real shift in what AI systems can take on independently.
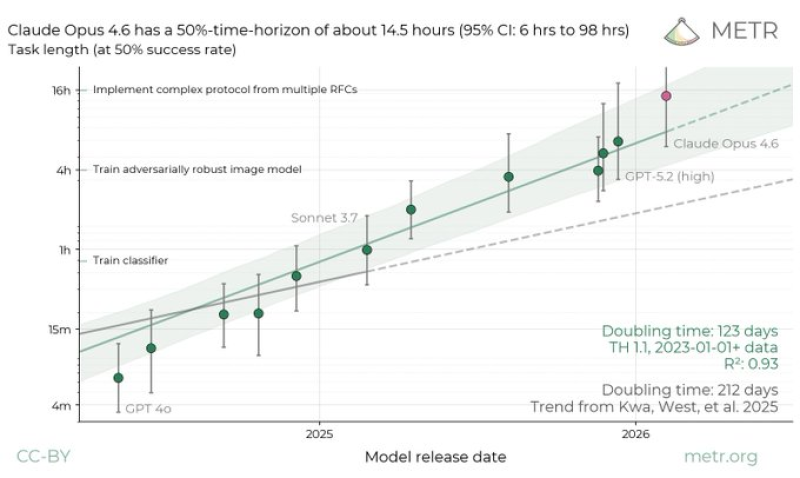
⬤ This performance puts Claude Opus 4.6 at the top of recent capability charts, a position reinforced by results across industry benchmarks. AI System Benchmarks: Claude Opus 4.6 Leads SWERFbench with 517 Score While Qwen3CoderNext Reaches 40 documents how the model stacks up against competing systems on structured test suites, underscoring that the extended task horizon isn't an isolated data point but part of a broader pattern of strong performance.
⬤ Real-world use cases are already illustrating what these longer horizons look like in practice. Claude Opus 4.6 Generates 10,000-Line Video Editing Application is one example showing the model completing sustained, project-level work rather than responding to isolated prompts. These aren't edge cases or demos - they reflect a genuine change in how AI handles open-ended technical assignments over time.
⬤ The upward trajectory in task horizon metrics points to a broader evolution in how AI is being evaluated and deployed. As models demonstrate they can sustain meaningful work across longer timeframes, expectations around practical utility shift accordingly. For companies integrating AI into research workflows, development pipelines, and product development, this trend has real strategic weight - and it's one that's only likely to accelerate as hardware and software ecosystems continue to mature.
 Marina Lyubimova
Marina Lyubimova


