 Peter Smith
Peter Smith

⬤ Anthropic reached a major milestone - its Opus 4.5 model achieved 95 % accuracy on the CORE-Bench Hard benchmark when it worked together with Claude Code. CORE-Bench is not a routine AI test - it checks whether an AI agent can reproduce the full cycle of scientific research, which includes setting up code running experiments and confirming results. The model first earned 78 % under automatic grading, but human reviewers raised the score to 95 % leaving earlier Anthropic models far behind.
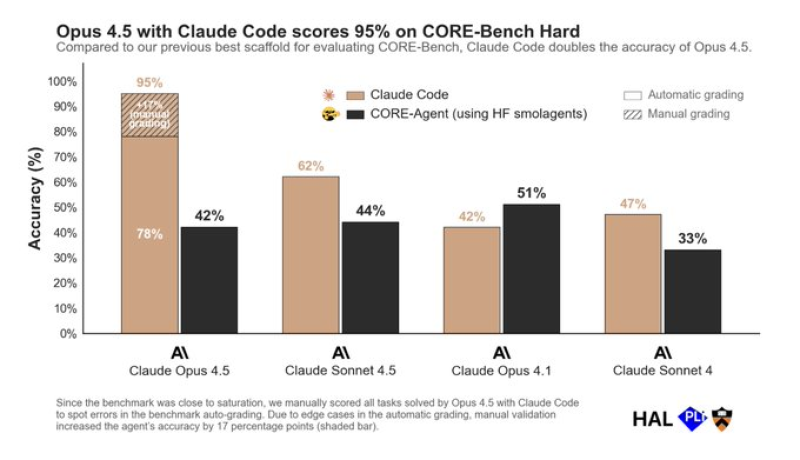
⬤ The performance gap is large. Sonnet 4.5 reached 62 %, while Opus 4.1 and Sonnet 4 stopped at 42 % and 47 %. Because top models found the benchmark too easy, researchers inspected every task that Opus 4.5 completed. That inspection showed the model executed complex scientific procedures more reliably than the auto grader noticed - the final score rose by 17 points.
⬤ The benchmark differs from standard AI tests because it demands real world effort. The model must run actual code, analyze experiment outputs plus validate final results - tasks that normally take scientists days or weeks. Claude Code gave Opus 4.5 a strong lift - it became the first model in this group to exceed 90 %. The result shows that AI agents now move past understanding scientific content and start to carry out full research workflows.

⬤ Stronger results on research benchmarks could accelerate automation of scientific workflows in universities and in companies. As models advance toward more capable autonomous systems, gains of this size could change expectations about development speed but also about competitive rank across the AI sector.
 Peter Smith
Peter Smith


