 Marina Lyubimova
Marina Lyubimova

⬤ Anthropic released Claude Opus 4.5. The model now leads the main coding leaderboards - it holds first place on SWE-Bench and on both ARC-AGI tests proving it can tackle hard software engineering tasks. Enterprise teams can reach it through AWS, Google Cloud besides Microsoft Azure.
⬤ The price fell sharply. Opus 4.5 charges about five dollars per million input tokens plus twenty-five dollars per million output tokens. That equals roughly one third of the Opus 4.1 price and about half of the Gemini 3 price. New architecture lets the model achieve the same work with fewer tokens, which lowers both compute demand but also running cost.
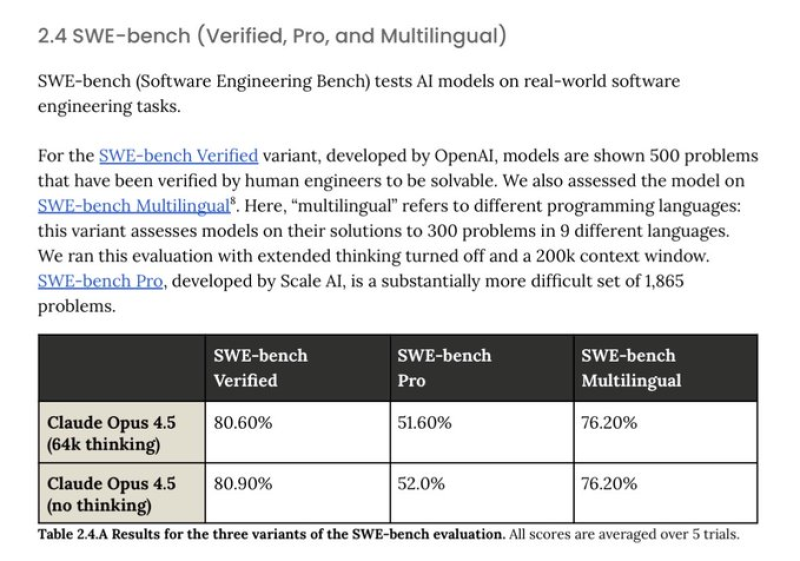
⬤ Benchmark results confirm the gain. When the model uses 64 k reasoning tokens it reaches 80.60 % on SWE-Bench Verified, 51.60 % on Pro and 76.20 % on Multilingual. It scores slightly higher without extended reasoning: 80.90 %, 52.00 % as well as 76.20 %. The model spends less time on backtracking and on long explanations - it reaches answers faster.
⬤ Those gains carry weight because coding skill or cost control have become central fronts in AI competition. Top scores broad cloud access and lower running costs together improve Anthropic's stance in the enterprise market. The model delivers stronger results with fewer tokens, a sign that the industry is moving toward smarter, lighter designs.
 Marina Lyubimova
Marina Lyubimova


