 Alex Dudov
Alex Dudov

⬤ Qwen has rolled out Qwen3-VL-Embedding and Qwen3-VL-Reranker, pushing forward multimodal retrieval and cross-modal understanding. Built on the Qwen3-VL foundation, these models handle text, images, screenshots, visual documents, videos, and mixed inputs in one unified system. Different data types get mapped into a shared representation space, making it possible to compare meaning across formats consistently.
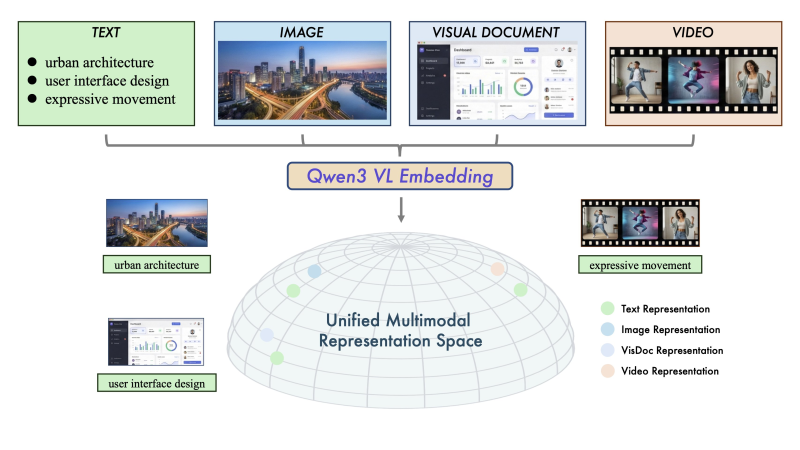
⬤ Qwen3-VL-Embedding uses a unified architecture that turns various data types into semantically aligned vectors. This lets you retrieve visual scenes, interface layouts, or video motion alongside text descriptions. The model works with over 30 languages and hits state-of-the-art benchmarks in multimodal retrieval, showing strong performance across both language and vision tasks.
⬤ The system runs on a two-stage pipeline. First, the embedding model creates dense vectors that capture high-level meaning across modalities. Then Qwen3-VL-Reranker calculates fine-grained relevance scores to sharpen ranking precision. Developers get configurable embedding dimensions, task-specific instruction options, and embedding quantization for efficiency in large-scale setups.

⬤ Use cases span image-text retrieval, video search, multimodal RAG systems, visual question answering, content clustering, and multilingual visual search. With support for mixed inputs like dashboards, screenshots, and motion-based video, Qwen3-VL fits real-world enterprise and research workflows where diverse data is standard. Open-source availability makes it easier to adopt and experiment across industries.
 Alex Dudov
Alex Dudov


