 Victoria Bazir
Victoria Bazir

⬤ OpenAI's newest Max Extra High model just grabbed the top spot on LiveBench's performance rankings with a 76.21 global average score. It's sitting just ahead of Anthropic's Opus 4.5 High Effort, which scored 75.58. The model pulled off a 90.80 in reasoning and 74.98 in coding, with agentic coding hitting 55.00. What's interesting here is how close the competition actually is—GPT-5.1 Codex Max High landed at 76.09, and Opus 4.5 Medium Effort came in at 74.87. We're talking about razor-thin margins that can flip the rankings with any update.
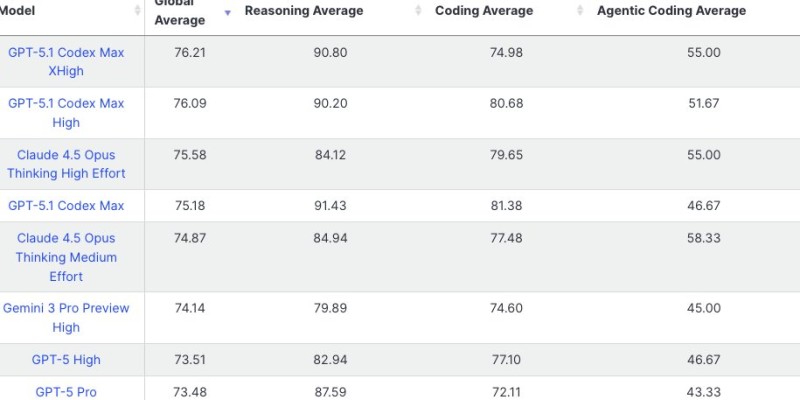
⬤ The numbers reveal where different models shine. GPT-5.1 Codex Max High crushed it on coding with an 80.68 average, while GPT-5 Pro dominated reasoning with 87.59. Each model seems built for specific strengths rather than trying to win everywhere. But there's a catch—running these top-tier systems isn't cheap. The Max Extra High model likely demands serious computational power and infrastructure, which translates to higher operational costs for anyone wanting peak performance.

⬤ Why does this matter? Because AI leadership keeps changing hands as companies roll out new versions and optimizations. These LiveBench shifts will influence how businesses pick their AI tools, especially for heavy reasoning tasks, massive coding projects, and the growing field of agentic applications. As the competition heats up, even small benchmark improvements could determine which platforms get adopted across the industry.
 Victoria Bazir
Victoria Bazir


