 Marina Lyubimova
Marina Lyubimova

Microsoft (NASDAQ: MSFT) researchers have unveiled ConStory-Bench, a new framework built to measure how well large language models maintain consistency when generating long-form stories. The benchmark arrives at a moment when AI systems are increasingly tasked with producing extended narratives, and the gaps in their storytelling logic are becoming harder to ignore.
2,000 Prompts, 19 Error Types Across 5 Categories
As Microsoft Research Releases UniG2U-Bench Spanning 7 Reasoning Regimes and 30 Subtasks, the company has been pushing benchmark development on multiple fronts. ConStory-Bench follows that trend, focusing specifically on narrative reliability. The system includes 2,000 prompts and an automated evaluation pipeline that detects 19 different types of consistency errors across five categories: timeline logic, world-building settings, character behavior, factual details, and narrative style.
The system builds evidence chains, highlighting the specific parts of the text that conflict and explaining why both statements cannot be true simultaneously.
The benchmark targets stories between roughly 8,000 and 10,000 words, a range that forces models to maintain coherence across complex plots and character arcs. The evaluation process starts with story generation, then runs the output through a dedicated consistency pipeline. That pipeline extracts story elements, pairs potentially conflicting statements, and determines whether they contradict each other.
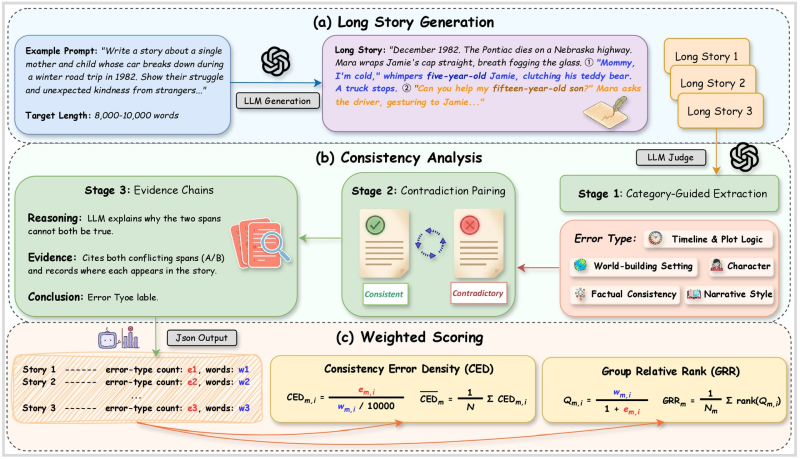
CED and GRR Metrics Set a New Standard for Narrative AI Evaluation
ConStory-Bench also introduces two scoring metrics: Consistency Error Density (CED), which tracks how often contradictions appear relative to story length, and Group Relative Rank (GRR), which compares narrative reliability across batches of generated content. Results are structured into standardized outputs, giving researchers a consistent basis for comparing different AI models.
This work connects to a broader pattern in AI development. Alongside Microsoft Launches Agent Lightning Open-Source Framework That Learns From 100 Failed Tasks and Microsoft Launches RhoAlpha First VLA Robotics Model With Tactile Sensing, ConStory-Bench reflects a growing industry-wide effort to evaluate not just what AI can generate, but how reliably it holds together over length and complexity.
 Marina Lyubimova
Marina Lyubimova


