 Marina Lyubimova
Marina Lyubimova

⬤ LG AI Research has rolled out K-EXAONE, its latest large-scale AI system that's making waves in the Mixture-of-Experts language model space. The model packs 236 billion total parameters but keeps things efficient by using just 23 billion active parameters during actual operation. It handles six languages and comes with an extended 256,000-token context window—a clear signal that LG designed this for heavy lifting with long-form content and complex tasks.
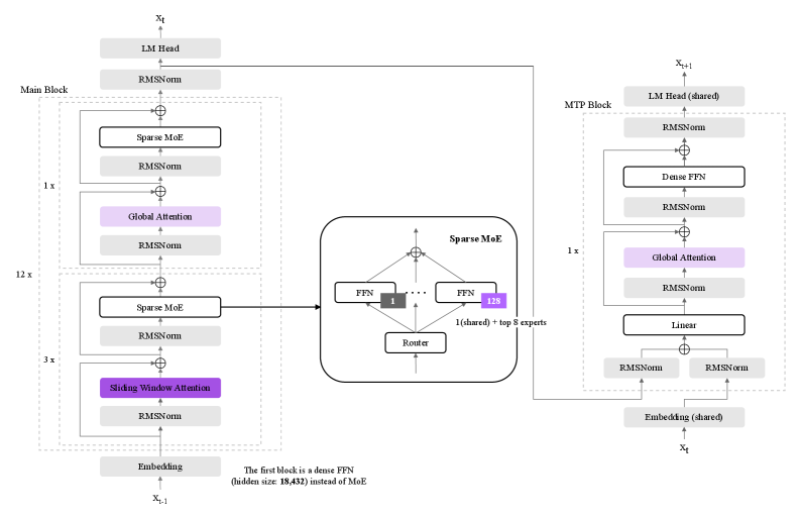
⬤ The technical specs reveal some clever engineering. K-EXAONE uses a hybrid attention system paired with Multi-Token Prediction, a technique that lets the model predict multiple tokens simultaneously instead of one at a time. This approach delivers roughly 1.5x faster throughput compared to traditional decoding methods. The Mixture-of-Experts routing is the secret sauce here—it lets the model scale up capacity without burning through proportional computing power, since only select expert modules activate for each input. Performance reportedly matches other open-weight models in the same size class.

⬤ That 256K context window stands out as one of K-EXAONE's biggest strengths. It can handle and remember far longer text streams than typical AI systems, making it a strong candidate for research work, enterprise knowledge processing, and analytical tasks that need sustained reference across massive input sequences. Combined with multilingual capabilities, this positions the model as a serious tool for demanding real-world applications.
 Marina Lyubimova
Marina Lyubimova


