 Peter Smith
Peter Smith

Despite rapid advances in AI capabilities, even the most powerful large language models continue to stumble on tasks that seem straightforward to humans. A new study from Caltech, Stanford, and Carleton College takes a hard look at why. The research introduces one of the first dedicated surveys on LLM reasoning failures, offering a structured way to understand where models go wrong and what might be done about it. For context on how newer models are competing in this space, see New LLM Fennec launches with 1M token context at half the price of competitors.
3 Reasoning Domains Where LLMs Break Down Most Often
The study organizes reasoning tasks into three broad domains, each revealing distinct weak points in current AI systems:
- Informal reasoning covers cognitive skills, cognitive bias, social norms, and theory-of-mind tasks where models frequently misjudge context or intent.
- Formal reasoning includes natural language logic, coding problems, and mathematical tasks where precision matters and errors compound quickly.
- Embodied reasoning involves spatial understanding, physical commonsense, and real-world environment interactions that current architectures handle poorly.
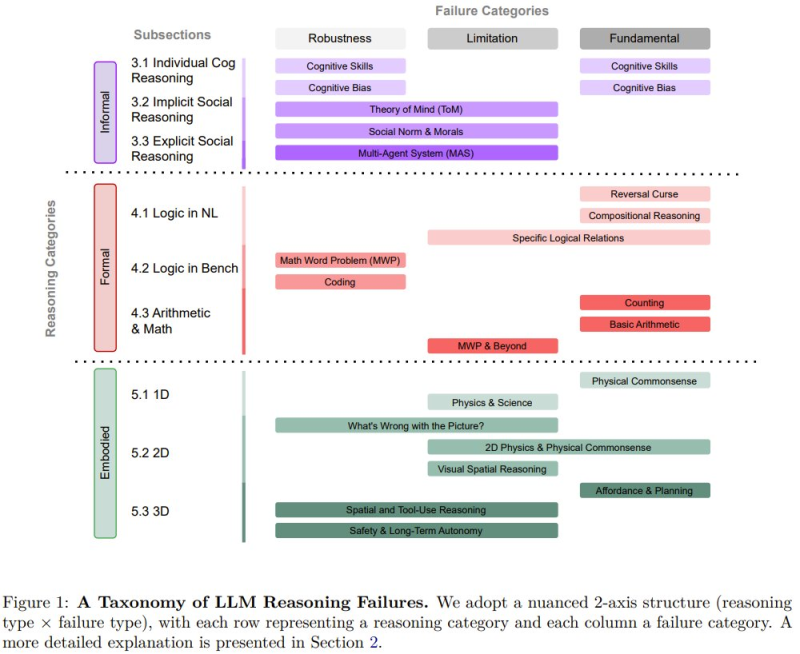
The taxonomy maps these domains across multiple task types to pinpoint where failures cluster most densely. Related work pushing AI training environments further includes Huawei researchers introduce CLI-Gym 1,655-task AI training framework.
Root Causes: Robustness, Domain Limits, and Architectural Constraints
Beyond categorizing task types, the researchers identify three underlying causes behind reasoning failures. Robustness issues arise when small prompt changes produce wildly inconsistent outputs. Application-specific limitations surface in narrow domains like social reasoning or advanced math, where models lack reliable internal models. Fundamental architectural weaknesses represent deeper structural constraints affecting performance across multiple task types at once.
The team also released a large open-source repository compiling existing reasoning failure research, giving the broader AI community a shared reference point to track and study recurring errors. The goal is to bring coherence to a fragmented body of literature and offer developers a clearer roadmap for building more reliable systems. For a broader look at how language models develop across their lifecycle, see New framework explains how 6-stage lifecycle makes large language models work.
 Peter Smith
Peter Smith


