 Saad Ullah
Saad Ullah

⬤ A recent scaling analysis from Anthropic examined how much revenue different AI models can generate when exploiting smart-contract vulnerabilities in a controlled simulation. The study ranks models by release date and reveals a clear log-linear trend: as models become more advanced, their potential exploit revenue increases sharply.
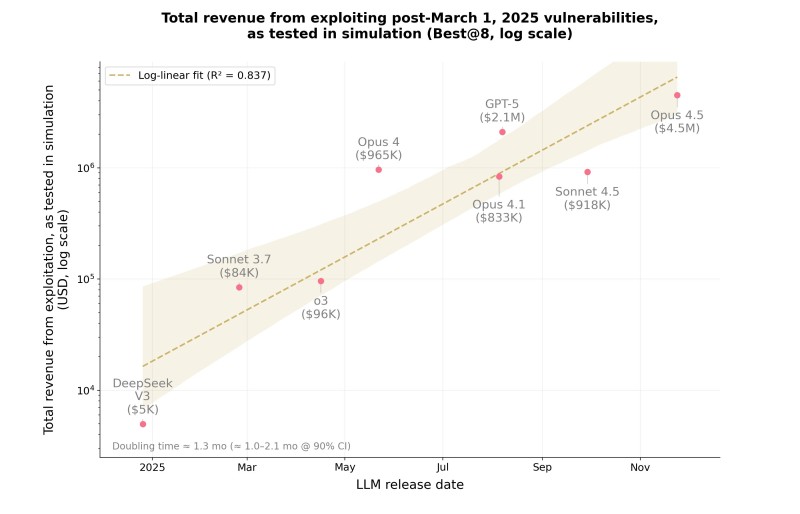
⬤ The chart shows early-2025 systems like DeepSeek V3 producing only around $5,000 in simulated exploit revenue, while mid-year models including Sonnet 3.7, O3, and Opus 4 range between roughly $80,000 and $965,000. More capable releases deliver substantially higher results. GPT-5 reaches an estimated $2.1 million, while Claude Opus 4.5 rises to approximately $4.5 million, topping the dataset. The dotted regression line indicates a doubling period of roughly 1.3 months, reflecting rapid capability growth across successive model generations.
⬤ The results reflect controlled testing rather than live exploitation, but they demonstrate that increasing model sophistication correlates with higher effectiveness in automated vulnerability exploitation tasks. The plotted data for Opus 4.1, Sonnet 4.5, GPT-5, and Opus 4.5 shows a tight cluster of late-2025 models operating at advanced capability levels.
⬤ These findings quantify a trend long discussed in AI safety circles: more capable models are increasingly effective at identifying and exploiting complex system vulnerabilities. The update reinforces the growing importance of rigorous evaluation frameworks as AI capabilities accelerate and the economic impact of automated exploit tasks becomes more substantial.
 Saad Ullah
Saad Ullah


