 Marina Lyubimova
Marina Lyubimova

Researchers from UniPat AI and Michigan State University introduced SWE-Vision, a system that enables vision-language models to write and execute Python code to analyze images at a granular level. As 机器之心 JIQIZHIXIN reported, the approach leverages libraries such as PIL and NumPy - allowing models to move beyond standard perception and reason about images programmatically instead.
SWE-Vision Benchmark Results Show Consistent Leads Over GPT-5.2
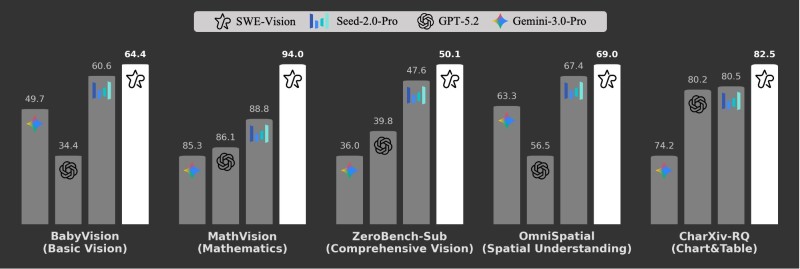
Benchmark results show SWE-Vision consistently outperforming competing models across five domains:
- BabyVision (basic vision): SWE-Vision 64.4 vs. Seed-2.0-Pro 60.6 and Gemini-3.0-Pro 49.7
- MathVision: SWE-Vision 94.0 vs. Seed-2.0-Pro 88.8 and GPT-5.2 86.1
- ZeroBench-Sub: SWE-Vision 50.1 vs. Seed-2.0-Pro 47.6 and GPT-5.2 39.8
The lead extends into more complex tasks as well. SWE-Vision achieves 69.0 in OmniSpatial, exceeding Seed-2.0-Pro at 67.4 and GPT-5.2 at 56.5. In CharXiv-RQ - focused on chart and table reasoning - it records 82.5, outperforming both GPT-5.2 at 80.2 and Seed-2.0-Pro at 80.5.
Code Execution Becomes the Key Differentiator in Visual AI Reasoning
The results reflect a broader trend toward integrating code execution into AI systems to enhance reasoning capabilities. By writing and running Python code against images rather than relying on perception alone, SWE-Vision treats visual analysis as a programmable problem - a fundamentally different approach from standard vision-language architectures.
By treating visual analysis as a programmable problem, SWE-Vision moves beyond perception into something closer to computational reasoning about images.
GPT-5.2 hits 33% on LiveCodeBench Pro shows how GPT-5.2 has been pushing boundaries in code-related tasks - making SWE-Vision's consistent leads over it across visual benchmarks a more meaningful signal about where the performance frontier is moving.
SWE-Vision Advances Reinforce Momentum in Next-Generation AI Models
The development reinforces momentum in the development of next-generation AI models where programmatic analysis and reasoning are becoming standard components rather than experimental add-ons.
Gemini 3 Pro reaches 82.2% accuracy on MADQA adds further context to the competitive landscape, showing how rapidly benchmark performance is advancing across the leading model families that SWE-Vision is now outpacing.
 Marina Lyubimova
Marina Lyubimova


