 Eseandre Mordi
Eseandre Mordi

⬤ Poetiq just became the top performer on the ARC-AGI-2 benchmark, with results verified by the ARC Prize organization. The system first hit 61% on the public dataset, then scored 54% on the tougher semi-private test set. That 54% still puts it ahead of every other competing model, marking a significant step forward in AI reasoning capabilities.
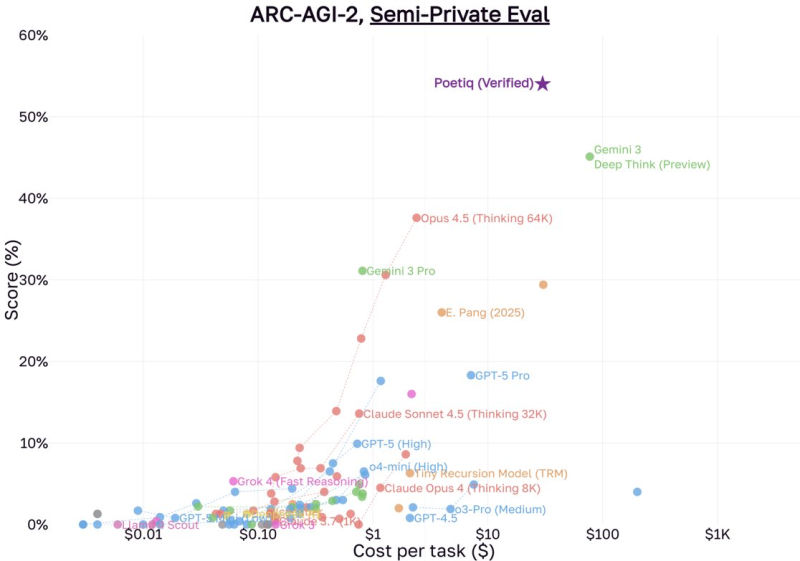
⬤ The semi-private ARC-AGI-2 leaderboard shows Poetiq at the top, outperforming Alphabet's Gemini 3 Deep Think (Preview), which scored in the 40–50% range. The gap between Poetiq's verified 54% and Gemini's result demonstrates how optimized model orchestration is pushing performance higher across the board.
⬤ Poetiq achieved this breakthrough using a custom scaffold that combines Gemini 3 Pro and GPT-5.1. The scaffold is now available as open source, with a detailed breakdown coming later this week. This hybrid approach shows that strategic model combinations and structured reasoning workflows can unlock advanced capabilities beyond what single models deliver.
⬤ Poetiq's lead on ARC-AGI-2 intensifies competition in advanced AI development. Performance on high-level reasoning benchmarks influences market expectations, R&D spending, and strategic decisions among major players like Alphabet. With open-source scaffolds like Poetiq's gaining traction, the race to turn benchmark wins into real-world applications is heating up across the AI sector.
 Eseandre Mordi
Eseandre Mordi


