 Victoria Bazir
Victoria Bazir

⬤ OpenSeeker has released a fully open-source frontier search agent, giving the research community complete access to training data, model weights, and methodology. Developed by an academic team, it delivers competitive results against top proprietary systems. As DailyPapers reported, the model reached state-of-the-art performance using only 11.7K training samples, a figure that underscores just how efficient the training design really is.
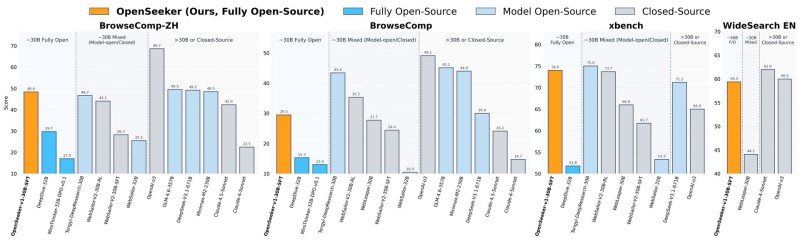
⬤ Benchmark scores confirm OpenSeeker's standing across four evaluation datasets: 48.4 on BrowseComp-ZH, 29.5 on BrowseComp, 74.0 on xbench, and 59.4 on WideSearch. On BrowseComp-ZH, it outscored Alibaba's Tongyi DeepResearch despite being trained on far fewer samples. BrowseComp itself tests complex multi-step web reasoning, asking models to navigate and synthesize scattered information across sources.
⬤ That efficiency gap is what makes the comparison striking. Where industrial models like Tongyi DeepResearch depend on heavy training pipelines, OpenSeeker took a leaner supervised fine-tuning route and still came out ahead in key categories. This fits a recognizable pattern in current AI development, one explored in coverage of Alibaba's Reg4Rec model with its 16.59% accuracy boost, where efficiency gains increasingly drive progress.
⬤ The broader significance of OpenSeeker lies in what full open-sourcing actually enables. By releasing both the model and the training data, the project lowers the barrier to entry and opens the door to wider experimentation. That trajectory, where capable models tackle increasingly complex real-world tasks, echoes developments like the AI system that generated $10,000 in 7 hours through real work tasks.
 Victoria Bazir
Victoria Bazir


