 Eseandre Mordi
Eseandre Mordi

⬤ New benchmark data shared across the AI community points to a striking contrast in GPT-5.4's performance. Charts from Artificial Analysis show the model often attempts answers even when it lacks reliable knowledge — which leads to fabricated responses. This pattern has drawn attention alongside earlier coverage noting that OpenAI rolled out GPT-5.4 Thinking with 92.8% on GPQA Diamond, underscoring how the system is built for aggressive reasoning and knowledge retrieval.
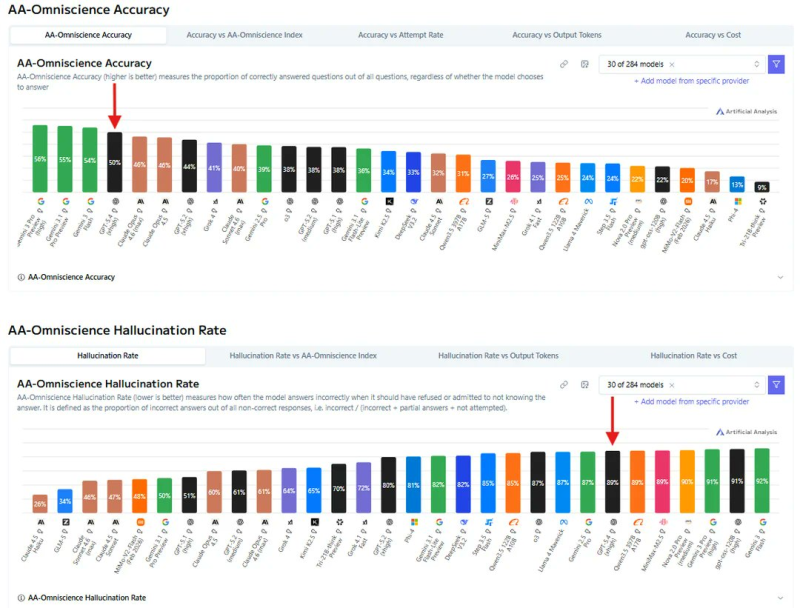
⬤ On the AA-Omniscience Accuracy benchmark — which measures correct answers across a wide range of topics and rewards models that acknowledge uncertainty rather than guess — GPT-5.4 scores roughly 50%, placing it among the stronger models in the comparison. Researchers focused on improving how AI handles complex and uncertain situations, including teams behind frameworks like Huawei's CLI-Gym 1,655-task AI training environment, are actively working to close gaps between benchmark results and real-world task performance.
⬤ The second benchmark tells a different story. GPT-5.4 records a hallucination rate close to 89% on the AA-Omniscience metric, placing it among the models most likely to generate wrong answers instead of declining to respond. This reflects a persistent tension in advanced language models: high knowledge depth does not automatically translate to reliable output when the model encounters uncertain prompts.
⬤ The GPT-5.4 discussion arrives as OpenAI continues expanding its next-generation AI lineup and internal structure. Recent organizational news included reports that OpenAI communications chief Hannah Wong is set to exit after 3 years. As models grow more capable, the gap between benchmark performance and genuine reliability remains one of the most debated questions across the AI research community.
 Eseandre Mordi
Eseandre Mordi


