 Usman Salis
Usman Salis

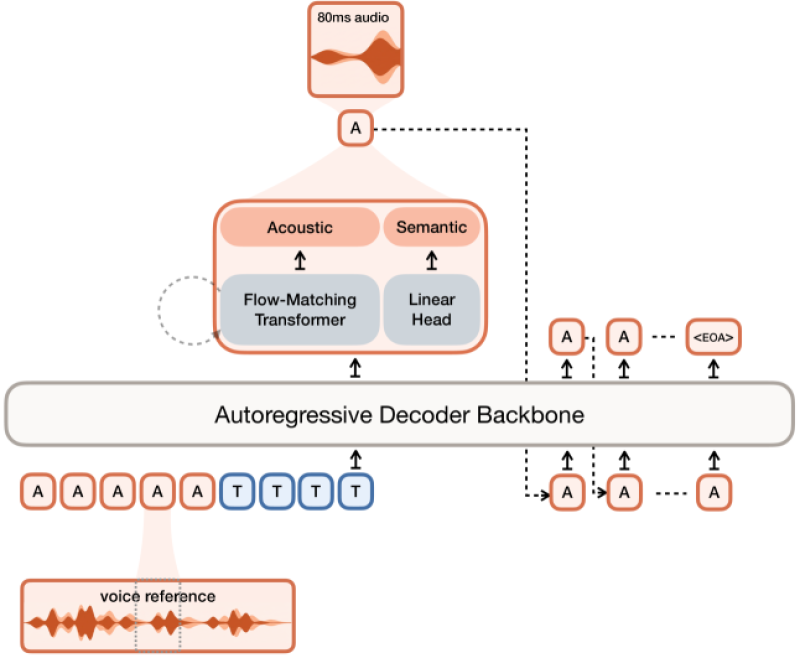
Mistral AI has introduced Voxtral TTS, a 4B parameter multilingual text-to-speech model built for natural and expressive voice generation. As DailyPapers reported, the system can generate speech from just three seconds of reference audio while maintaining low latency. That combination - minimal input, fast output, and strong expressiveness - sets it apart from most existing solutions in the text-to-speech space.
The model is designed to replicate voice characteristics from very limited reference data, which makes deployment significantly faster and more flexible. Whether for customer-facing products, content creation pipelines, or real-time communication tools, Voxtral TTS removes one of the most common bottlenecks in voice AI - the need for long, high-quality recordings to clone or adapt a voice effectively.
How Voxtral TTS Speech Model Beats ElevenLabs in Human Evaluation
In benchmark testing, Voxtral TTS achieved a 62.8% win rate over ElevenLabs Flash v2.5 in human preference evaluations - a margin wide enough to indicate a genuine quality gap, not just a marginal improvement.
Human raters consistently preferred Voxtral's output for its naturalness and expressive range. The model also outperforms GPT-4o mini in speech quality benchmarks, with Mistral's earlier speech model already demonstrating a 4% error rate advantage - placing the Voxtral family firmly at the competitive edge of today's speech AI landscape.
Key capabilities of Voxtral TTS include:
- Voice cloning from as little as 3 seconds of reference audio
- Native multilingual support across major languages
- Low-latency generation optimized for real-time applications
- Reduced input requirements compared to existing TTS solutions
Improvements in quality and latency are critical in the rapidly evolving speech AI landscape - and Voxtral TTS addresses both simultaneously, without requiring large volumes of reference audio to get started.
Efficiency Gains: The Central Theme in Mistral AI Speech Technology
The Voxtral TTS release reflects a broader shift in the industry toward more efficient and accessible AI-generated speech. As models improve in output quality while requiring less input data, their adoption across consumer apps, enterprise tools, and developer platforms is expected to grow steadily. The economics of deployment become more attractive when you no longer need hours of studio-quality recordings to achieve convincing voice synthesis.
This pattern mirrors a wider trend in technology more broadly. From AI research to hardware innovation, efficiency has become the defining competitive advantage. As seen in fields like aerospace - where Elon Musk targets a 4,000x drop in space launch costs - dramatic gains in cost and resource efficiency are reshaping entire industries. AI speech is no different.
As models continue to improve in quality while reducing input requirements, their adoption across platforms is expected to expand - and Voxtral TTS is a strong signal of exactly that trajectory.
With a 4B parameter architecture that consistently outperforms larger competitors in human preference tests, Voxtral TTS makes a compelling case that the next phase of speech AI will be won not by scale alone - but by the ability to deliver high quality with minimal friction, fast deployment, and real-time performance that actually works in production.
 Usman Salis
Usman Salis


