 Eseandre Mordi
Eseandre Mordi
⬤ New benchmark data making rounds on X shows a striking performance gap between competing AI models, particularly between Grok and Alphabet's GOOGL Gemini systems. The results indicate Grok 4 and Grok 4 Fast both deliver lower hallucination rates than Gemini 3 Pro, while the latest Grok 4.1 achieves a major leap in accuracy. Charts accompanying the data position Grok models near the top for truthfulness, while Gemini and several other major systems show higher rates of false responses.
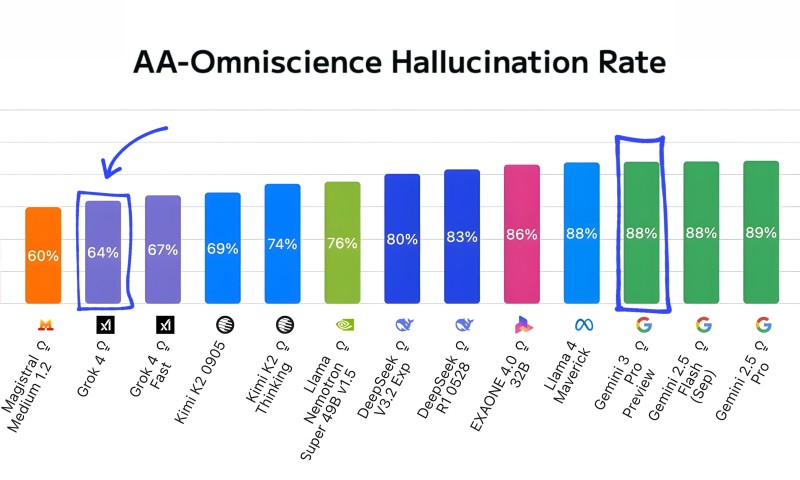
⬤ The numbers tell a clear story: Grok 4 hits a 64% hallucination rate, with Grok 4 Fast at 67%, both comfortably ahead of Gemini 3 Pro Preview and Gemini 2.5 variants hovering around 88%. What's more concerning for Alphabet is that Gemini 3 Pro appears to have inherited the same accuracy issues from Gemini 2.5 Pro without meaningful progress. Meanwhile, Grok 4.1 slashes hallucinations by 3× compared to Grok 4 Fast, marking substantial improvement in reducing AI-generated errors on knowledge-intensive tasks.
⬤ The benchmark includes other industry models like Llama, Kimi, DeepSeek, and EXAONE, showing varied performance across the board. But the spotlight stays on the gap between Grok and Gemini lines. With Gemini 3 Pro preview showing no improvement over previous versions, the data highlights ongoing challenges Alphabet faces in boosting model reliability.
⬤ These accuracy differences could reshape conversations around AI trustworthiness and practical applications. As competition heats up, hallucination rates matter more than ever for enterprise adoption, regulatory review, and standing out in the market. The latest findings may set expectations for upcoming Gemini updates while putting pressure on major platforms to close accuracy gaps in real-world use.
 Eseandre Mordi
Eseandre Mordi


