 Eseandre Mordi
Eseandre Mordi

⬤ Google's Gemini 3 model looks set to push AI performance forward, based on new benchmark estimates. Projections show Gemini 3 beating GPT-5 and GPT-5.1 on multiple reasoning-focused tests, including ARC-AGI-1, ARC-AGI-2, HLE, and SWE-Bench. Expected scores put Gemini 3 at 82% on ARC-AGI-1, 32% on ARC-AGI-2, roughly 32.5% on HLE with tools off, and 83% on SWE-Bench. These numbers point to solid progress in structured reasoning, scientific inference, and code-solving tasks.
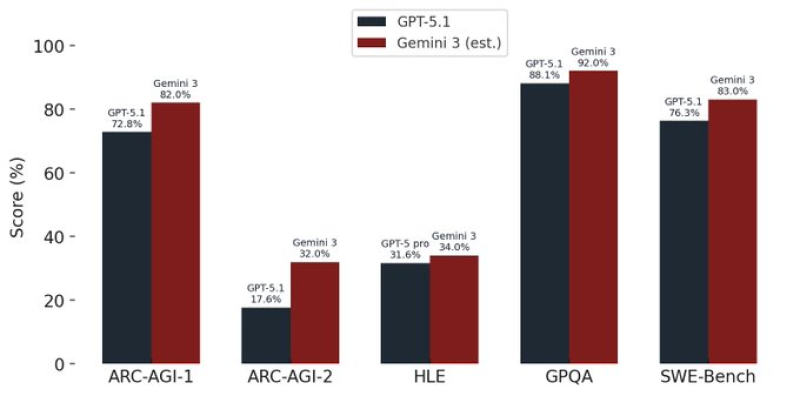
⬤ The benchmark chart shows clear gaps between Gemini 3 and GPT-5.1. On ARC-AGI-1, Gemini 3 hits 82% while GPT-5.1 reaches 72.8%. ARC-AGI-2 shows an even bigger difference—Gemini 3 at 32% versus GPT-5.1 at 17.6%. For HLE, Gemini 3 comes in near 34% while GPT-5.1 Pro scores 31.6%. In GPQA, GPT-5.1 records 88.1% compared to Gemini 3's estimated 92%. On SWE-Bench, Gemini 3 is projected at 83% against GPT-5.1's 76.3%. Across all metrics, Gemini 3 shows consistent advantages in analytical reasoning and scientific understanding.
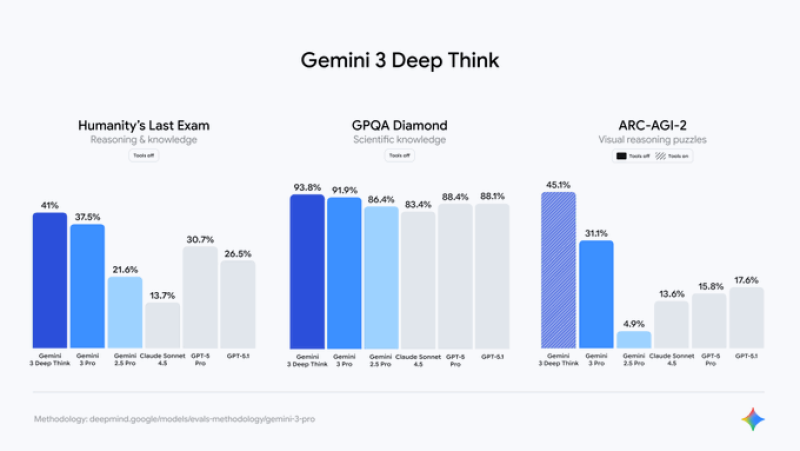
⬤ Deep Think evaluations back up these trends. In Humanity's Last Exam, Gemini 3 Deep Think reaches 41%, ahead of Gemini 3 Pro at 37.5% and well above GPT-5.1 at 26.5%. GPQA Diamond puts Gemini 3 Deep Think at 93.8%, topping all competing models in the chart. For ARC-AGI-2 visual reasoning puzzles with tools enabled, Gemini 3 Deep Think scores 45.1% while Gemini 3 Pro hits 31.1%. These results match the performance gains shown earlier, especially in areas that benefit from deeper cognitive modeling.
⬤ Growing expectations around Gemini 3 signal a shift in frontier AI competition. The model's projected gains in reasoning-heavy benchmarks could change how organizations evaluate AI systems for research, automation, applied science, and code generation. If these estimates prove accurate, Gemini 3 may represent a real step toward models optimized for consistent, high-precision reasoning across complex tasks—not just generative output.
 Eseandre Mordi
Eseandre Mordi


