 Usman Salis
Usman Salis

⬤ A recently published AI research paper called "DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models" introduces DiffThinker, a system that treats reasoning like an image-to-image creation process. The paper points out that many multimodal language models read images but spit out text-based reasoning, which can cause them to lose track of visual details during lengthy reasoning chains. DiffThinker flips the script by generating a complete visual solution — think maze paths or finished Sudoku grids — then a simple parser program reads the image to check accuracy.
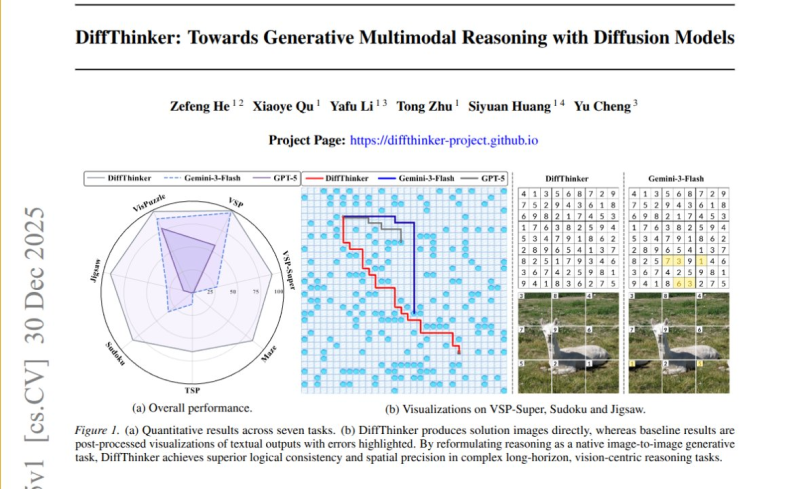
⬤ DiffThinker runs on a diffusion model that starts with random noise and slowly polishes it into a final solution image. Researchers put it through seven different tasks: grid navigation, mazes, traveling-salesperson-style routes, Sudoku puzzles, and jigsaw challenges. They stacked it up against GPT-5, Gemini-3-Flash, and fine-tuned Qwen3-VL models. The results? DiffThinker delivered 314.2% better accuracy than GPT-5 and 111.6% better than Gemini-3-Flash on average. The team also emphasized its predictable runtime thanks to a fixed number of diffusion steps and its ability to test multiple reasoning paths simultaneously.
⬤ The paper showcases visual examples like maze solving, Sudoku completion, and jigsaw reconstruction. DiffThinker creates solution images directly, while competing models produce text outputs that need extra processing afterward. Researchers argue that image-native reasoning keeps logical and spatial consistency intact, especially for long-term, vision-heavy reasoning problems. A performance radar chart demonstrates DiffThinker dominating other models across categories including VSP-Super, VSP, Sudoku, and maze challenges.
⬤ This research matters because it shows diffusion-based models might have real advantages over text-focused multimodal systems when tasks depend on maintaining visual context. As AI research digs deeper into multimodal reasoning beyond just language, approaches like DiffThinker could reshape how future reasoning architectures handle complex problem-solving scenarios.
 Usman Salis
Usman Salis


